Мультикаст трафик. Технология Multicast: рациональная передача мегапиксельного видеотрафика
В предыдущих двух статьях мы построили головную станцию (стример) и научились транслировать услугу IPTV Unicast-ом при помощи relaying. По большому счету, многим небольшим провайдерам этого достаточно, особенно если представить, что услуга IPTV носит некоммерческий, а маркетинговый характер. Однако для того, чтобы предложить своим клиентам качественный, легко управляемый, коммерческий продукт, с большим выбором пакетов телепрограмм, изложенный ранее метод не подходит. На помощь таким провайдерам приходит трансляция IPTV при помощи multicast рассылок.
Multicast
На вопрос, что же такое Multicast легко найти ответ, так, например, Википедия считает, что это специальная форма широковещания, при которой сетевой пакет одновременно направляется определённому подмножеству адресатов - не одному (unicast), и не всем (broadcast). С данной формулировкой трудно не согласиться. Технология IP Multicast очень выгодна в использовании, когда один и тот же набор данных должны получать сотни и тысячи подписчиков на эти данные, без увеличения нагрузки на сеть. Довольно трудно себе представить сервер, способный выдать хотя бы пятимегабитный поток данных тысячам потребителей. Так как обслуживание двухсторонних соединений процесс довольно ресурсоемкий, да еще и дублирование одних и тех же данных явное свидетельство нерациональной расточительности.
IP Multicast - это диапазон IP адресов с 224.0.0.0 до 239.255.255.255. Для того, чтоб использовать Multicast рассылки в Вашей сети необходимо выполнить ряд условий:
Сегмент сети, в котором планируется использование Multicast, должен быть построен на управляемых коммутаторах;
Управляемые коммутаторы должны поддерживать протокол IGMP, при помощи которого определяется членство в Multicast группе порта.
Подходы к реализации Multicast вещания
На сегодняшний день существует несколько технологий доставки Multicast трафика подписчикам, основные из них это:
- PIM-DM в связке с IGMP-snooping;
- PIM-SM в связке с IGMP-snooping;
Попробуем коротко разобраться с этими подходами. Для маршрутизации multicast трафика существует специальный протокол - PIM. В свою очередь PIM имеет два режима работы:
PIM-SM (sparse mode) или режим, при котором рассылка начинается только тогда, когда появляется запрос на членство в группе.
Разница в этих режимах работы заключается в том, что при использовании режима PIM-DM multicast роутер рассылает все зарегистрированные на нем multicast группы и только потом отсекает те, в которые никто не подписался. Напротив, режим PIM-SM рассылает multicast потоки только после того, когда на него придет IGMP запрос на членство в группе multicast рассылки. Также существует еще одно существенное отличие между режимами PIM-DM и PIM-SM, заключается оно в том, что для режима PIM-SM необходима так называемая точка рандеву - RENDEZVOUS POINT (RP) . Точка рандеву - это место, где регистрируются все источники Multicast потоков. Таким образом, все Multicast потоки собираются в этой точке и из нее выдаются членам группы. В итоге, потребители Multicast потоков абсолютно ничего не знают об источнике потока.
Также существует еще один способ доставки IPTV потребителям - это MVR или, если перевести аббревиатуру, Регистрация Мультикастовых VLAN’ов . Суть данного способа заключается в том, что multicast трафик бежит по сети в отдельном VLAN, а вот уже MVR подмешивает этот трафик в порты, запросивших определенную Multicast группу клиентов.
Поскольку в рамки статьи не входит рассмотрение каждого из описанных выше подходов, то остановимся только на одном из них.
Реализация трансляции с использованием PIM-SM.
Для данной реализации использовался коммутатор BD-COM S3928GX, который вполне сгодиться для ядра довольно таки не маленькой сети, так как это полноценный L3 свитч на борту которого можно установить 4*10G порта XFP, а при условии, что цена очень гуманна, альтернатив сегодня не так уж и много.
На рисунке представлена примерная схема реализации:
Настройка коммутатора сводиться к следующим шагам:
1. Создадим VLAN 111 и включим в него наш стример порт 23.
2. Включим потребителя IPTV в уже существующий дефолтный VLAN 1 порт 21
3. Определим в каком режиме будет работать маршрутизация Multicast
router pim-sm4. Включим в VLAN 1 поддержку IGMP
ip igmp enable5. На VLAN 111 настроим поддержку PIM
Собственно, на этом настройка коммутатора заканчивается, а ниже я приведу полный конфиг свитча.
Switch#show conf!version 2.1.0B build 7185
service timestamps log date
service timestamps debug date
!
no spanning-tree
!
aaa authentication login default local
aaa authentication enable default none
!
username XXXX password 0 XXXX
!
ip multicast-routing
!
interface Null0
!
interface GigaEthernet0/1
!
.
.
.
interface GigaEthernet0/20
!
interface GigaEthernet0/21
!
interface GigaEthernet0/22
!
interface GigaEthernet0/23
switchport pvid 111
!
interface GigaEthernet0/24
!
interface TGigaEthernet1/1
!
interface TGigaEthernet1/2
!
interface TGigaEthernet2/1
!
interface TGigaEthernet2/2
!
interface VLAN1
ip address 192.168.2.168 255.255.255.0
no ip directed-broadcast
ip igmp enable
!
interface VLAN111
ip address 10.10.10.1 255.255.255.0
no ip directed-broadcast
ip igmp enable
!
!
!
vlan 1,111
!
!
ip igmp-snooping
no ip igmp-proxy enable
!
ip route default 192.168.2.10
ip exf
!
router pim-sm
reg-rate-limit 1
!
Switch#
Теперь пришло время проверить, а все ли работает так, как нам хотелось. Потребителем IPTV будет выступать компьютер с установленным Linux и программой VLC Player (www.videolan.org). Для удобства просмотра я подготовил маленький плэйлист с двумя ранее настроенными каналами:
#EXTM3U
#EXTINF:5, Первый
udp://@239.255.1.90:1234
#EXTINF:5, Euronews
udp://@239.255.1.91:1234
Загрузив плэйлись в плэйер, на экране появился «Первый» канал. Теперь осталось убедиться в том, что мы все правильно настроили и в наш порт прилетает единственная multicast группа. Для это запустим tcpdump и посмотрим, а что же твориться на нашем сетевом интерфейсе.
# tcpdump -ni eth0
17:43:24.413102 IP 10.10.10.2.39109 > 239.255.1.90
.1234: UDP, length 1316
17:43:24.413147 IP 10.10.10.2.39109 > 239.255.1.90
.1234: UDP, length 1316
17:43:24.418339 IP 10.10.10.2.39109 > 239.255.1.90
.1234: UDP, length 1316
17:43:24.418384 IP 10.10.10.2.39109 > 239.255.1.90
.1234: UDP, length 1316
Теперь переключим канал и опять глянем в tcpdump
# tcpdump -ni eth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
17:42:46.130451 IP 10.10.10.2.47782 > 239.255.1.91
.1234: UDP, length 1316
17:42:46.130495 IP 10.10.10.2.47782 > 239.255.1.91
.1234: UDP, length 1316
17:42:46.135728 IP 10.10.10.2.47782 > 239.255.1.91
.1234: UDP, length 1316
17:42:46.135782 IP 10.10.10.2.47782 > 239.255.1.91
.1234: UDP, length 1316
Как видим, при переключении телеканала IGMP отключается от одной группы и подключается к другой.
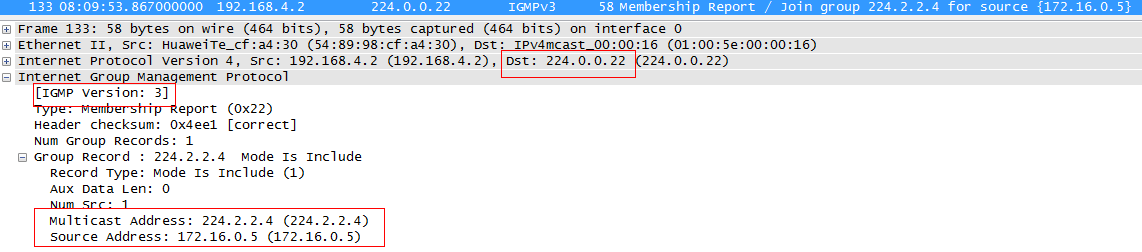
Версия 3 поддерживает всё то, что поддерживает IGMPv2, но есть и ряд изменений. Во-первых, Report отправляется уже не на адрес группы, а на мультикастовый служебный адрес 224.0.0.22 . А адрес запрашиваемой группы указан только внутри пакета. Делается это для упрощения работы IGMP Snooping, о котором мы поговорим .
Во-вторых, что более важно, IGMPv3 стал поддерживать SSM в чистом виде. Это так называемый . В этом случае клиент может не просто запросить группу, но также указать список источников, от которых он хотел бы получать трафик или наоборот не хотел бы. В IGMPv2 клиент просто запрашивает и получает трафик группы, не заботясь об источнике.
Итак, IGMP предназначен для взаимодействия клиентов и маршрутизатора. Поэтому, возвращаясь к Примеру II , где нет маршрутизатора, мы можем авторитетно заявить - IGMP там - не более, чем формальность. Маршрутизатора нет, и клиенту не у кого запрашивать мультикастовый поток. А заработает видео по той простой причине, что поток и так льётся от коммутатора - надо только подхватить его.
Напомним, что IGMP не работает для IPv6. Там существует протокол MLD .
Повторим ещё раз
*Дамп отфильтрован по IGMP*
.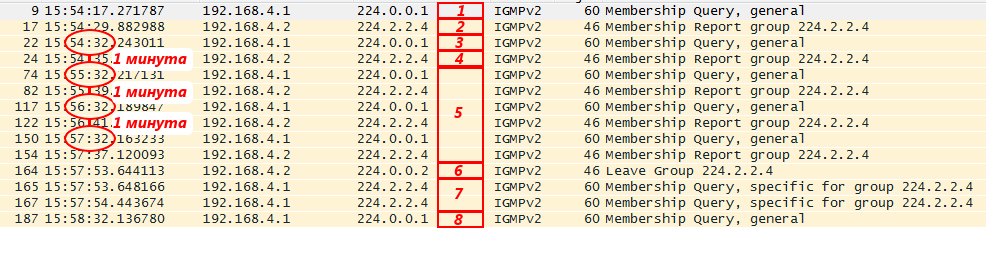
1.
Первым делом маршрутизатор отправил свой IGMP General Query после включения IGMP на его интерфейсе, чтобы узнать, есть ли получатели и заявить о своём желании быть Querier. На тот момент никого не было в этой группе.
2.
Далее появился клиент, который захотел получать трафик группы 224.2.2.4 и он отправил свой IGMP Report. После этого пошёл трафик на него, но он отфильтрован из дампа.
3.
Потом маршрутизатор решил зачем-то проверить - а нет ли ещё клиентов и отправил IGMP General Query ещё раз, на который клиент вынужден ответить (4
).
5.
Периодически (раз в минуту) маршрутизатор проверяет, что получатели по-прежнему есть, с помощью IGMP General Query, а узел подтверждает это с помощью IGMP Report.
6.
Потом он передумал и отказался от группы, отправив IGMP Leave.
7.
Маршрутизатор получил Leave и, желая убедиться, что больше никаких других получателей нет, посылает IGMP Group Specific Query… дважды. И по истечении таймера перестаёт передавать трафик сюда.
8.
Однако передавать IGMP Query в сеть он по-прежнему продолжает. Например, на тот случай, если вы плеер не отключали, а просто где-то со связью проблемы. Потом связь восстанавливается, но клиент-то Report не посылает сам по себе. А вот на Query отвечает. Таким образом поток может восстановиться без участия человека.
И ещё раз
IGMP - протокол, с помощью которого маршрутизатор узнаёт о наличии получателей мультикастового трафика и об их отключении.- посылается клиентом при подключении и в ответ на IGMP Query. Означает, что клиент хочет получать трафик конкретной группы.
- посылается маршрутизатором периодически, чтобы проверить какие группы сейчас нужны. В качестве адреса получателя указывается 224.0.0.1.
IGMP Group Sepcific Query - посылается маршрутизатором в ответ на сообщение Leave, чтобы узнать есть ли другие получатели в этой группе. В качестве адреса получателя указывается адрес мультикастовой группы.
- посылается клиентом, когда тот хочет покинуть группу.
Querier - если в одном широковещательном сегменте несколько маршрутизаторов, который могут вещать, среди них выбирается один главный - Querier. Он и будет периодически рассылать Query и передавать трафик.
Подробное описание всех терминов IGMP .
PIM
Итак, мы разобрались, как клиенты сообщают ближайшему маршрутизатору о своих намерениях. Теперь неплохо было бы передать трафик от источника получателю через большую сеть.Если вдуматься, то мы стоим перед довольной сложной проблемой - источник только вещает на группу, он ничего не знает о том, где находятся получатели и сколько их.
Получатели и ближайшие к ним маршрутизаторы знают только, что им нужен трафик конкретной группы, но понятия не имеют, где находится источник и какой у него адрес.
Как в такой ситуации доставить трафик?
Существует несколько протоколов маршрутизации мультикастового трафика: DVMRP , MOSPF , CBT - все они по-разному решают такую задачу. Но стандартом де факто стал PIM - Protocol Independent Multicast
.
Другие подходы настолько нежизнеспособны, что порой даже их разработчики практически признают это. Вот, например, выдержка из RFC по протоколу CBT:
CBT version 2 is not, and was not, intended to be backwards compatible with version 1; we do not expect this to cause extensive compatibility problems because we do not believe CBT is at all widely deployed at this stage.
PIM имеет две версии, которые можно даже назвать двумя различными протоколами в принципе, уж сильно они разные:
- PIM Dense Mode (DM)
- PIM Sparse Mode (SM)
PIM Dense Mode
пытается решить проблему доставки мультиакста в лоб. Он заведомо предполагает, что получатели есть везде, во всех уголках сети. Поэтому изначально он наводняет всю сеть мультикастовым трафиком, то есть рассылает его во все порты, кроме того, откуда он пришёл. Если потом оказывается, что где-то он не нужен, то эта ветка «отрезается» с помощью специального сообщения PIM Prune - трафик туда больше не отправляется.Но через некоторое время в эту же ветку маршрутизатор снова пытается отправить мультикаст - вдруг там появились получатели. Если не появились, ветка снова отрезается на определённый период. Если клиент на маршрутизаторе появился в промежутке между этими двумя событиями, отправляется сообщение Graft - маршрутизатор запрашивает отрезанную ветку обратно, чтобы не ждать, пока ему что-то перепадёт.
Как видите, здесь не стоит вопрос определения пути к получателям - трафик достигнет их просто потому, что он везде.
После «обрезания» ненужных ветвей остаётся дерево, вдоль которого передаётся мультикастовый трафик. Это дерево называется SPT - Shortest Path Tree
.
Оно лишено петель и использует кратчайший путь от получателя до источника. По сути оно очень похоже на Spanning Tree в STP , где корнем является источник.
SPT - это конкретный вид дерева - дерево кратчайшего пути. А вообще любое мультикастовое дерево называется .
Предполагается, что PIM DM должен использоваться в сетях с высокой плотностью мультикастовых клиентов, что и объясняет его название (Dense). Но реальность такова, что эта ситуация - скорее, исключение, и зачастую PIM DM нецелесообразен.
Что нам действительно важно сейчас - это механизм избежания петель.
Представим такую сеть:

Один источник, один получатель и простейшая IP-сеть между ними. На всех маршрутизаторах запущен PIM DM.
Что произошло бы, если бы не было специального механизма избежания петель?
Источник отправляет мультикастовый трафик. R1 его получает и в соответствии с принципами PIM DM отправляет во все интерфейсы, кроме того, откуда он пришёл - то есть на R2 и R3.
R2 поступает точно так же, то есть отправляет трафик в сторону R3. R3 не может определить, что это тот же самый трафик, который он уже получил от R1, поэтому пересылает его во все свои интерфейсы. R1 получит копию трафика от R3 и так далее. Вот она - петля.
Что же предлагает PIM в такой ситуации? RPF - Reverse Path Forwarding
. Это главный принцип передачи мультикастового трафика в PIM (любого вида: и DM и SM) - трафик от источника должен приходить по кратчайшему пути.
То есть для каждого полученного мультикастового пакета производится проверка на основе таблицы маршрутизации, оттуда ли он пришёл.
1) Маршрутизатор смотрит на адрес источника мультикастового пакета.
2) Проверяет таблицу маршрутизации, через какой интерфейс доступен адрес источника.
3) Проверяет интерфейс, через который пришёл мультикастовый пакет.
4) Если интерфейсы совпадают - всё отлично, мультикастовый пакет пропускается, если же данные приходят с другого интерфейса - они будут отброшены.
В нашем примере R3 знает, что кратчайший путь до источника лежит через R1 (статический или динамический маршрут). Поэтому мультикастовые пакеты, пришедшие от R1, проходят проверку и принимаются R3, а те, что пришли от R2, отбрасываются.
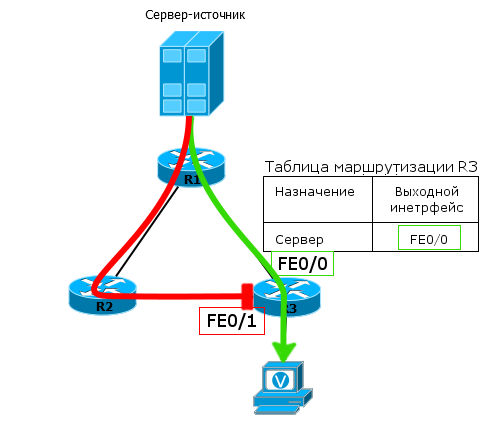
Такая проверка называется RPF-Check
и благодаря ей даже в более сложных сетях петли в MDT не возникнут.
Этот механизм важен нам, потому что он актуален и в PIM-SM и работает там точно также.
Как видите, PIM опирается на таблицу юникастовой маршрутизации, но, во-первых, сам не маршрутизирует трафик, во-вторых, ему не важно, кто и как наполнял таблицу.
Останавливаться здесь и подробно рассматривать работу PIM DM мы не будем - это устаревший протокол с массой недостатков (ну, как RIP).
Однако PIM DM может применяться в некоторых случаях. Например, в совсем небольших сетях, где поток мультикаста небольшой.

PIM Sparse Mode
Совершенно другой подход применяет PIM SM . Несмотря на название (разреженный режим), он с успехом может применяться в любой сети с эффективностью как минимум не хуже, чем у PIM DM.Здесь отказались от идеи безусловного наводнения мультикастом сети. Заинтересованные узлы самостоятельно запрашивают подключение к дереву с помощью сообщений PIM Join .
Если маршрутизатор не посылал Join, то и трафик ему отправляться не будет.
Для того, чтобы понять, как работает PIM, начнём с уже знакомой нам простой сети с одним PIM-маршрутизатором: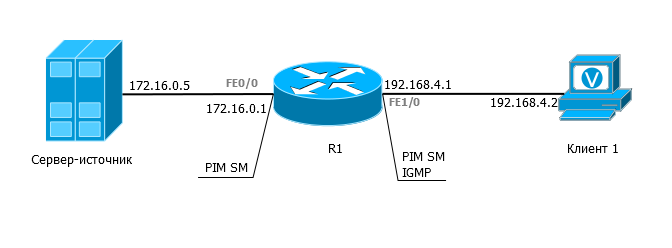
Из настроек на R1 надо включить возможность маршрутизации мультикаста, PIM SM на двух интерфейсах (в сторону источника и в сторону клиента) и IGMP в сторону клиента. Помимо прочих базовых настроек, конечно (IP, IGP).
С этого момента вы можете расчехлить GNS и собирать лабораторию. Достаточно подробно о том, как собрать стенд для мультикаста я рассказал в этой статье .
R1(config)#ip multicast-routing
R1(config)#int fa0/0
R1(config-if)#ip pim sparse-mode
R1(config-if)#int fa1/0
R1(config-if)#ip pim sparse-mode
Cisco тут как обычно отличается своим особенным подходом: при активации PIM на интерфейсе, автоматически активируется и IGMP. На всех интерфейсах, где активирован PIM, работает и IGMP.
В то же время у других производителей два разных протокола включаются двумя разными командами: отдельно IGMP, отдельно PIM.
Простим Cisco эту странность? Вместе со всеми остальными?Плюс, возможно, потребуется настроить адрес RP (ip pim rp-address 172.16.0.1 , например). Об этом позже, пока примите как данность и смиритесь.
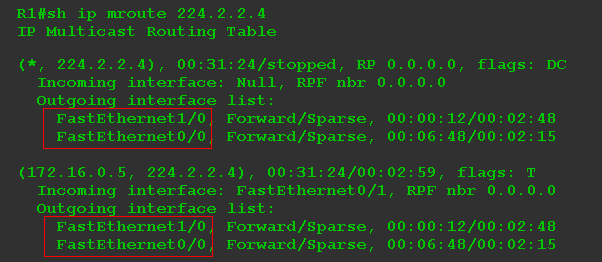
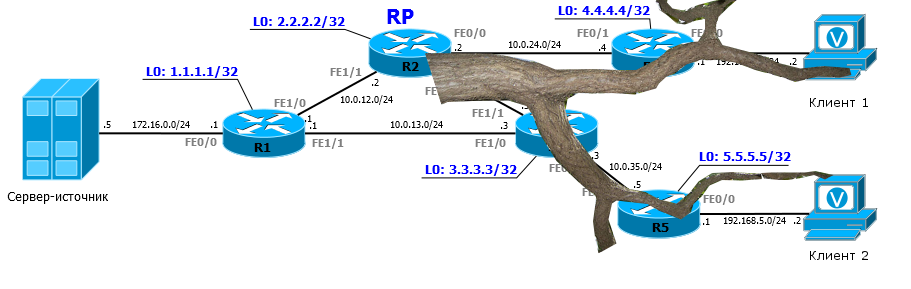
Проверим текущее состояние таблицы мультикастовой маршрутизации для группы 224.2.2.4:

После того, как на источнике вы запустите вещание, надо проверить таблицу ещё раз.

Давайте разберём этот немногословный вывод.
Запись вида (*, 225.0.1.1)
называется , /читается старкомаджи
/ и сообщает нам о получателях. Причём не обязательно речь об одном клиенте-компьютере, вообще это может быть и, например, другой PIM-маршрутизатор. Важно то, в какие интерфейсы надо передавать трафик.
Если список нисходящих интерфейсов (OIL) пуст - Null
, значит нет получателей - а мы их пока не запускали.
Запись (172.16.0.5, 225.0.1.1) называется , /читается эскомаджи / и говорит о том, что известен источник. В нашем случае источник с адресом 172.16.0.5 вещает трафик для группы 224.2.2.4. Мультикастовый трафик приходит на интерфейс FE0/1 - это восходящий (Upstream ) интерфейс.
Итак, нет клиентов. Трафик от источника доходит до маршрутизатора и на этом его жизнь кончается. Давайте добавим теперь получателя - настроим приём мультикаста на ПК.
ПК отсылает IGMP Report, маршрутизатор понимает, что появились клиенты и обновляет таблицу мультикастовой маршрутизации.
Теперь она выглядит так:

Появился и нисходящий интерфейс: FE0/0, что вполне ожидаемо. Причём он появился как в (*, G), так и в (S, G). Список нисходящих интерфейсов называется OIL - Outgoing Interface List .
Добавим ещё одного клиента на интерфейс FE1/0:
(S, G): Когда мультикастовый трафик с адресом назначения 224.2.2.4 от источника 172.16.0.5 приходит на интерфейс FE0/1, его копии нужно отправить в FE0/0 и FE1/0.
Но это был очень простой пример - один маршрутизатор сразу знает и адрес источника и где находятся получатели. Фактически даже деревьев тут никаких нет - разве что вырожденное. Но это помогло нам разобраться с тем, как взаимодействуют PIM и IGMP.
Чтобы разобраться с тем, что такое PIM, обратимся к сети гораздо более сложной

Предположим, что уже настроены все IP-адреса в соответствии со схемой. На сети запущен IGP для обычной юникастовой маршрутизации.
Клиент1
, например, может пинговать Сервер-источник.

Но пока не запущен PIM, IGMP, клиенты не запрашивают каналы.
Итак, момент времени 0.
Включаем мультикастовую маршрутизацию на всех пяти маршрутизаторах:
RX(config)#ip multicast-routing
PIM включается непосредственно на всех интерфейсах всех маршрутизаторов (в том числе на интерфейсе в сторону Сервера-источника и клиентов):
RX(config)#int FEX/X
RX(config-if)#ip pim sparse-mode
IGMP, по идее должен включаться на интерфейсах в сторону клиентов, но, как мы уже отметили выше, на оборудовании Cisco он включается автоматически вместе с PIM.
Первое, что делает PIM - устанавливает соседство. Для этого используются сообщения . При активации PIM на интерфейсе с него отправляется PIM Hello на адрес 224.0.0.13 с TTL равным 1. Это означает, что соседями могут быть только маршрутизаторы, находящиеся в одном широковещательном домене.
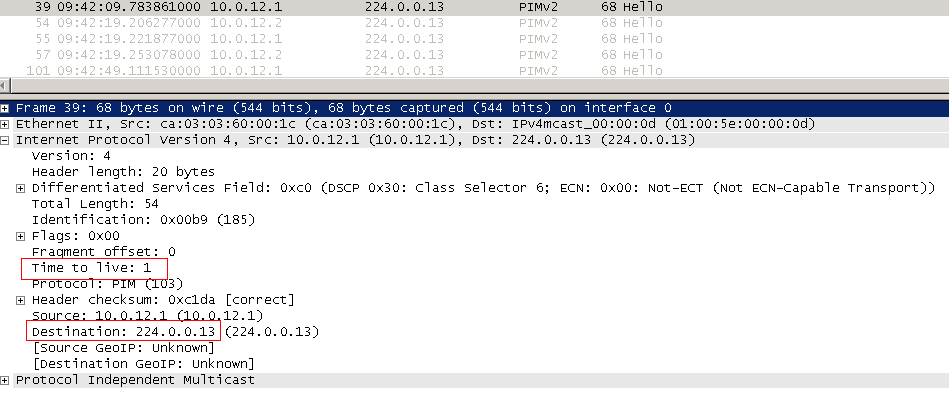
Как только соседи получили приветствия друг от друга:

Теперь они готовы принимать заявки на мультикастовые группы.
Если мы сейчас запустим в вольер клиентов с одной стороны и включим мультикастовый поток с сервера с другой, то R1 получит поток трафика, а R4 получит IGMP Report при попытке клиента подключиться. В итоге R1 не будет знать ничего о получателях, а R4 об источнике.
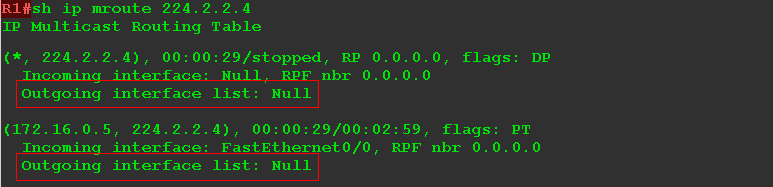
Неплохо было бы если бы информация об источнике и о клиентах группы была собрана где-то в одном месте. Но в каком?
Такая точка встречи называется Rendezvous Point - RP
. Это центральное понятие PIM SM. Без неё ничего бы не работало. Здесь встречаются источник и получатели.
Все PIM-маршрутизаторы должны знать, кто является RP в домене, то есть знать её IP-адрес.
Чтобы построить дерево MDT, в сети выбирается в качестве RP некая центральная точка, которая,
- отвечает за изучение источника,
- является точкой притяжения сообщений Join от всех заинтересованных.
Пусть пока R2 будет выполнять роль RP.
Чтобы увеличить надёжность, обычно выбирается адрес Loopback-интерфейса. Поэтому на всех
маршрутизаторах выполняется команда:
RX(config)#ip pim rp-address 2.2.2.2
Естественно, этот адрес должен быть доступен по таблице маршрутизации со всех точек.
Ну и поскольку адрес 2.2.2.2 является RP, на интерфейсе Loopback 0
на R2 желательно тоже активировать PIM.
R2(config)#interface Loopback 0 RX(config-if)#ip pim sparse-mode
Сразу после этого R4 узнает об источнике трафика для группы 224.2.2.4:
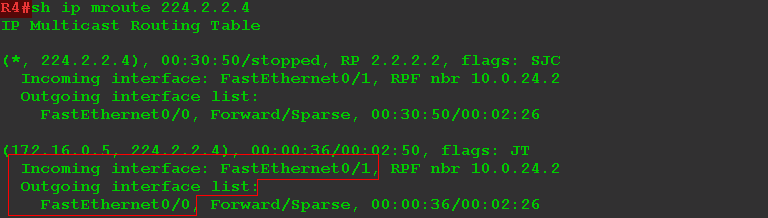
И даже передаёт трафик:
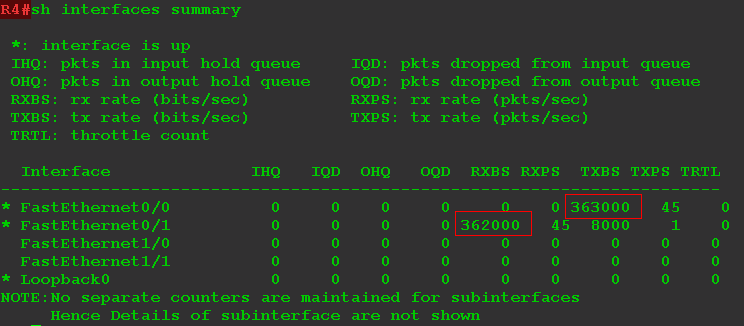
На интерфейс FE0/1 приходит 362000 б/с, и через интерфейс FE0/0 они передаются.
Всё, что мы сделали:
Включили возможность маршрутизации мультикастового трафика (ip multicast-routing
)
Активировали PIM на интерфейсах (ip pim sparse-mode
)
Указали адрес RP (ip pim rp-adress X.X.X.X
)
Всё, это уже рабочая конфигурация и можно приступать к разбору, ведь за кулисами скрывается гораздо больше, чем видно на сцене.
Полная конфигурация с PIM.
Разбор полётов
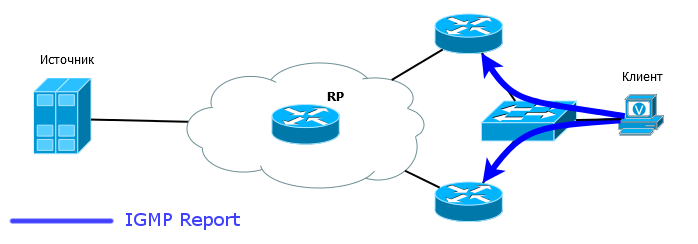
Ну так и как же в итоге всё работает? Как RP узнаёт где источник, где клиенты и обеспечивает связь между ними?Поскольку всё затевается ради наших любимых клиентов, то, начав с них, рассмотрим в деталях весь процесс.
1) Клиент 1 отправляет IGMP Report для группы 224.2.2.4
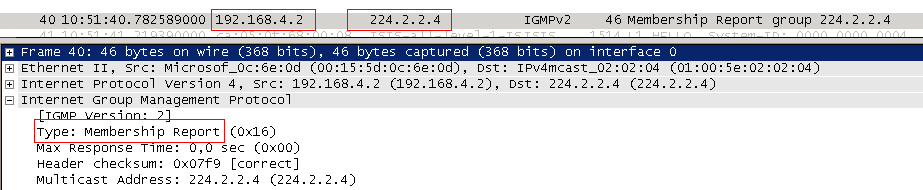
2) R4 получает этот запрос, понимает, что есть клиент за интерфейсом FE0/0, добавляет этот интерфейс в OIL и формирует запись (*, G).

Здесь видно восходящий интерфейс FE0/1, но это не значит, что R4 получает трафик для группы 224.2.2.4. Это говорит лишь о том, что единственное место, откуда сейчас он может получать - FE0/1, потому что именно там находится RP. Кстати, здесь же указан и сосед, который прошёл RPF-Check - R2: 10.0.2.24. Ожидаемо.
R4 называется - LHR (Last Hop Router) - последний маршрутизатор на пути мультикастового трафика, если считать от источника. Иными словами - это маршрутизатор, ближайший к получателю. Для Клиента1 - это R4, для Клиента2 - это R5.
3) Поскольку на R4 пока нет мультикастового потока (он его не запрашивал прежде), он формирует сообщение PIM Join и отправляет его в сторону RP (2.2.2.2).
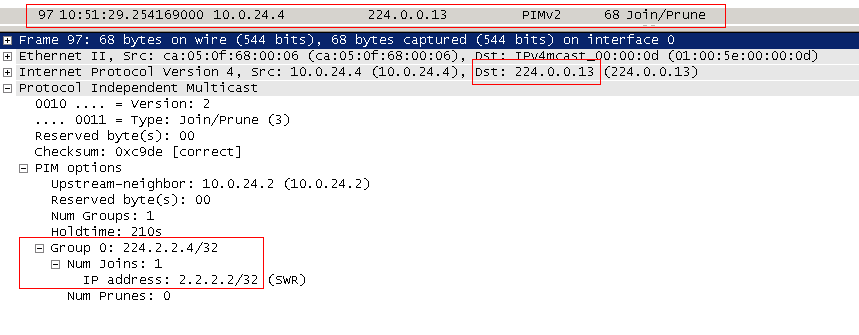
PIM Join отправляется мультикастом на адрес 224.0.0.13. «В сторону RP» означает через интерфейс, который указан в таблице маршрутизации, как outbound для того адреса, который указан внутри пакета. В нашем случае это 2.2.2.2 - адрес RP. Такой Join обозначается ещё как Join (*,G)
и говорит: «Не важно, кто источник, мне нужен трафик группы 224.2.2.4».
То есть каждый маршрутизатор на пути должен обработать такой Join и при необходимости отправить новый Join в сторону RP. (Важно понимать, что если на маршрутизаторе уже есть эта группа, он не будет отправлять выше Join - он просто добавит интерфейс, с которого пришёл Join, в OIL и начнёт передавать трафик).
В нашем случае Join ушёл в FE0/1:
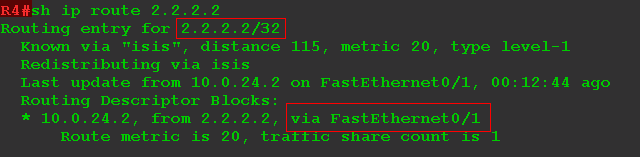
4) R2, получив Join, формирует запись (*, G) и добавляет интерфейс FE0/0 в OIL. Но Join отсылать уже некуда - он сам уже RP, а про источник пока ничего не известно.
Таким образом RP узнаёт о том, где находятся клиенты.
Если Клиент 2
тоже захочет получать мультикастовый трафик для той же группы, R5 отправит PIM Join в FE0/1, потому что за ним находится RP, R3, получив его, формирует новый PIM Join и отправляет в FE1/1 - туда, где находится RP.
То есть Join путешествует так узел за узлом, пока не доберётся до RP или до другого маршрутизатора, где уже есть клиенты этой группы.

Итак, R2 - наш RP - сейчас знает о том, что за FE0/0 и FE1/0 у него есть получатели для группы 224.2.2.4.
Причём неважно, сколько их там - по одному за каждым интерфейсом или по сто - поток трафика всё равно будет один на интерфейс.
Если изобразить графически то, что мы получили, то это будет выглядеть так:
Отдалённо напоминает дерево, не так ли? Поэтому оно так и называется - RPT - Rendezvous Point Tree
. Это дерево с корнем в RP, а ветви которого простираются до клиентов.
Более общий термин, как мы упоминали выше, - MDT - Multicast Distribution Tree
- дерево, вдоль которого распространяется мультикастовый поток. Позже вы увидите разницу между MDT и RPT.
5)
Теперь врубаем сервер. Как мы уже выше обсуждали, он не волнуется о PIM, RP, IGMP - он просто вещает. А R1 получает этот поток. Его задача - доставить мультикаст до RP.
В PIM есть специальный тип сообщений - Register
. Он нужен для того, чтобы зарегистрировать источник мультикаста на RP.
Итак, R1 получает мультикастовый поток группы 224.2.2.4:

R1 является FHR (First Hop Router) - первый маршрутизатор на пути мультикастового трафика или ближайший к источнику.

Обратите внимание на стек протоколов. Поверх юникастового IP и заголовка PIM идёт изначальный мультикастовый IP, UDP и данные.
Теперь, в отличие от всех других, пока известных нам сообщений PIM, в адресе получателя указан 2.2.2.2, а не мультикастовый адрес.
Такой пакет доставляется до RP по стандартным правилам юникастовой маршрутизации и несёт в себе изначальный мультикастовый пакет, то есть это… это же туннелирование!
На сервере 172.16.0.5 работает приложение, которое может передавать пакеты только на широковещательный адрес 255.255.255.255, с портом получателя UDP 10999.
Этот трафик надо доставить к клиентам 1 и 2:
Клиенту 1 в виде мультикаст трафика с адресом группы 239.9.9.9.
А в сегмент клиента 2, в виде широковещательных пакетов на адрес 255.255.255.255.
Замечание к топологии : в этой задаче только маршрутизаторы R1, R2, R3 находятся под управлением администраторов нашей сети. То есть, конфигурацию изменять можно только на них.
Сервер 172.16.0.5 передает мультикаст трафик на группы 239.1.1.1 и 239.2.2.2.
Настроить сеть таким образом, чтобы трафик группы 239.1.1.1 не передавался в сегмент между R3 и R5, и во все сегменты ниже R5.
Но при этом, трафик группы 239.2.2.2 должен передаваться без проблем.
То же, что Source DR, только для получателей мультикастового трафика - LHR (Last Hop Router)
.
Пример топологии:
Receiver DR ответственен за отправку на RP PIM Join. В вышеприведённой топологии, если оба маршрутизатора отправят Join, то оба будут получать мультикастовый трафик, но в этом нет необходимости. Только DR отправляет Join. Второй просто мониторит доступность DR.
Поскольку DR отправляет Join, то он же и будет вещать трафик в LAN. Но тут возникает закономерный вопрос - а что, если PIM DR"ом стал один, а IGMP Querier"ом другой? А ситуация-то вполне возможна, ведь для Querier чем меньше IP, тем лучше, а для DR, наоборот.
В этом случае DR"ом выбирается тот маршрутизатор, который уже является Querier и такая проблема не возникает.

Правила выбора Receiver DR точно такие же, как и Source DR.
Проблема двух одновременно передающих маршрутизаторов может возникнуть и в середине сети, где нет ни конечных клиентов, ни источников - только маршрутизаторы.
Очень остро этот вопрос стоял в PIM DM, где это была совершенно рядовая ситуация из-за механизма Flood and Prune.
Но и в PIM SM она не исключена.
Рассмотрим такую сеть:

Здесь три маршрутизатора находятся в одном сегменте сети и, соответственно, являются соседями по PIM. R1 выступает в роли RP.
R4 отправляет PIM Join в сторону RP. Поскольку этот пакет мультикастовый он попадает и на R2 и на R3, и оба они обработав его, добавляют нисходящий интерфейс в OIL.
Тут бы должен сработать механизм выбора DR, но и на R2 и на R3 есть другие клиенты этой группы, и обоим маршрутизаторам так или иначе придётся отправлять PIM Join.
Когда мультикастовый трафик приходит от источника на R2 и R3, в сегмент он передаётся обоими маршрутизаторами и задваивается там. PIM не пытается предотвратить такую ситуацию - тут он действует по факту свершившегося преступления - как только в свой нисходящий интерфейс для определённой группы (из списка OIL) маршрутизатор получает мультикастовый трафик этой самой группы, он понимает: что-то не так - другой отправитель уже есть в этом сегменте.
Тогда маршрутизатор отправляет специальное сообщение .
Такое сообщение помогает выбрать PIM Forwarder
- тот маршрутизатор, который вправе вещать в данном сегменте.
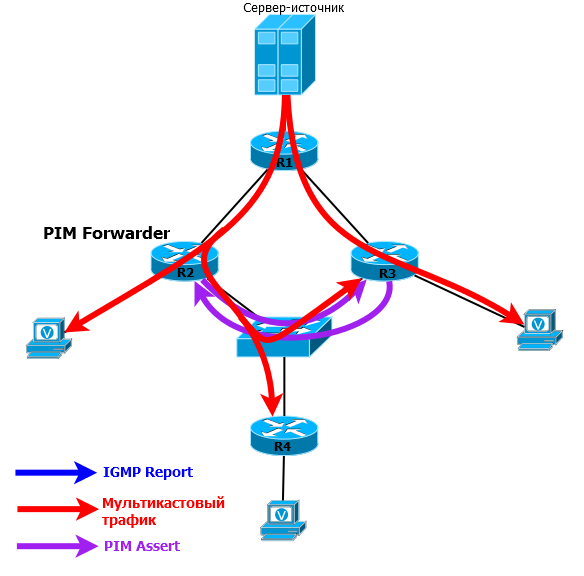
Не надо его путать с PIM DR. Во-первых, PIM DR отвечает за отправку сообщений PIM Join и Prune , а PIM Forwarder - за отправку трафика . Второе отличие - PIM DR выбирается всегда и в любых сетях при установлении соседства, А PIM Forwrder только при необходимости - когда получен мультикастовый трафик с интерфейса из списка OIL.
Выбор RP
Выше мы для простоты задавали RP вручную командой ip pim rp-address X.X.X.X .И вот как выглядела команда :
Но представим совершенно невозможную в современных сетях ситуацию - R2 вышел из строя. Это всё - финиш. Клиент 2
ещё будет работать, поскольку произошёл SPT Switchover, а вот всё новое и всё, что шло через RP сломается, даже если есть альтернативный путь.
Ну и нагрузка на администратора домена. Представьте себе: на 50 маршрутизаторах перебить вручную как минимум одну команду (а для разных групп ведь могут быть разные RP).
Динамический выбор RP позволяет и избежать ручной работы и обеспечить надёжность - если одна RP станет недоступна, в бой вступит сразу же другая.
В данный момент существует один общепризнанный протокол, позволяющий это сделать - . Циска в прежние времена продвигала несколько неуклюжий Auto-RP , но сейчас он почти не используется, хотя циска этого не признаёт, и в мы имеем раздражающий рудимент в виде группы 224.0.1.40.
Надо на самом деле отдать должное протоколу Auto-RP. Он был спасением в прежние времена. Но с появлением открытого и гибкого Bootstrap, он закономерно уступил свои позиции.
Итак, предположим, что в нашей сети мы хотим, чтобы R3 подхватывал функции RP в случае выхода из строя R2.
R2 и R3 определяются как кандидаты на роль RP - так они и называются C-RP . На этих маршрутизаторах настраиваем:
RX(config)interface Loopback 0 RX(config-if)ip pim sparse-mode RX(config-if)exit RX(config)#ip pim rp-candidate loopback 0
Но пока ничего не происходит - кандидаты пока не знают, как уведомить всех о себе.
Чтобы информировать все мультикастовые маршрутизаторы домена о существующих RP вводится механизм BSR - BootStrap Router . Претендентов может быть несколько, как и C-RP. Они называются соответственно C-BSR . Настраиваются они похожим образом.
Пусть BSR у нас будет один и для теста (исключительно) это будет R1.
R1(config)interface Loopback 0
R1(config-if)ip pim sparse-mode
R1(config-if)exit
R1(config)#ip pim bsr-candidate loopback 0
Сначала из всех C-BSR выбирается один главный BSR, который и будет всем заправлять. Для этого каждый C-BSR отправляет в сеть мультикастовый BootStrap Message (BSM)
на адрес 224.0.0.13 - это тоже пакет протокола PIM. Его должны принять и обработать все мультикастовые маршрутизаторы и после разослать во все порты, где активирован PIM. BSM передаётся не в сторону чего-то (RP или источника), в отличии, от PIM Join, а во все стороны. Такая веерная рассылка помогает достигнуть BSM всех уголков сети, в том числе всех C-BSR и всех C-RP. Для того, чтобы BSM не блуждали по сети бесконечно, применяется всё тот же механизм RPF - если BSM пришёл не с того интерфейса, за которым находится сеть отправителя этого сообщения, такое сообщение отбрасывается.

С помощью этих BSM все мультикастовые маршрутизаторы определяют самого достойного кандидата на основе приоритетов. Как только C-BSR получает BSM от другого маршрутизатора с бОльшим приоритетом, он прекращает рассылать свои сообщения. В результате все обладают одинаковой информацией.
На этом этапе, когда выбран BSR, благодаря тому, что его BSM разошлись уже по всей сети, C-RP знают его адрес и юникастом отправляют на него сообщения Candidte-RP-Advertisement , в которых они несут список групп, которые они обслуживают - это называется group-to-RP mapping . BSR все эти сообщения агрегирует и создаёт RP-Set - информационную таблицу: какие RP каждую группу обслуживают.
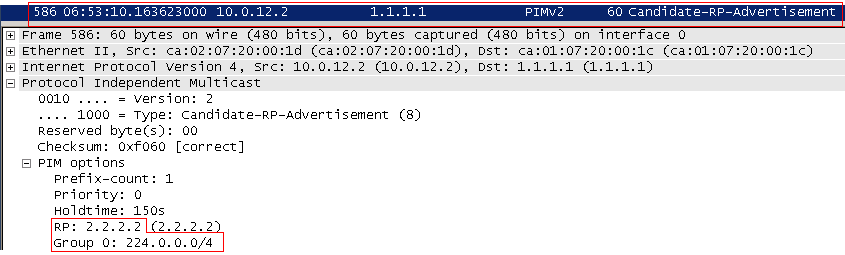
Далее BSR в прежней веерной манере рассылает те же BootStrap Message, которые на этот раз содержат RP-Set. Эти сообщения успешно достигают всех мультикастовых маршрутизаторов, каждый из которых самостоятельно делает выбор, какую RP нужно использовать для каждой конкретной группы.

BSR периодически делает такие рассылки, чтобы с одной стороны все знали, что информация по RP ещё актуальна, а с другой C-BSR были в курсе, что сам главный BSR ещё жив.
RP, кстати, тоже периодически шлют на BSR свои анонсы Candidate-RP-Advertisement.
Фактически всё, что нужно сделать для настройки автоматического выбора RP - указать C-RP и указать C-BSR - не так уж много работы, всё остальное за вас сделает PIM.
Как всегда, в целях повышения надёжности рекомендуется указывать интерфейсы Loopback в качестве кандидатов.
Завершая главу PIM SM, давайте ещё раз отметим важнейшие моменты
- Должна быть обеспечена обычная юникастовая связность с помощью IGP или статических маршрутов. Это лежит в основе алгоритма RPF.
- Дерево строится только после появления клиента. Именно клиент инициирует построение дерева. Нет клиента - нет дерева.
- RPF помогает избежать петель.
- Все маршрутизаторы должны знать о том, кто является RP - только с её помощью можно построить дерево.
- Точка RP может быть указана статически, а может выбираться автоматически с помощью протокола BootStrap.
- В первой фазе строится RPT - дерево от клиентов до RP - и Source Tree - дерево от источника до RP. Во второй фазе происходит переключение с построенного RPT на SPT - кратчайший путь от получателя до источника.
Ещё перечислим все типы деревьев и сообщений, которые нам теперь известны.
MDT - Multicast Distribution Tree
. Общий термин, описывающий любое дерево передачи мультикаста.
SPT - Shortest Path Tree
. Дерево с кратчайшим путём от клиента или RP до источника. В PIM DM есть только SPT. В PIM SM SPT может быть от источника до RP или от источника до получателя после того, как произошёл SPT Switchover. Обозначается записью - известен источник для группы.
Source Tree
- то же самое, что SPT.
RPT - Rendezvous Point Tree
. Дерево от RP до получателей. Используется только в PIM SM. Обозначается записью .
Shared Tree
- то же, что RPT. Называется так потому, что все клиенты подключены к одному общему дереву с корнем в RP.
Типы сообщений PIM Sparse Mode:
Hello
- для установления соседства и поддержания этих отношений. Также необходимы для выбора DR.
- запрос на подключение к дереву группы G. Не важно кто источник. Отправляется в сторону RP. С их помощью строится дерево RPT.
- Source Specific Join. Это запрос на подключение к дереву группы G с определённым источником - S. Отправляется в сторону источника - S. С их помощью строится дерево SPT.
Prune (*, G)
- запрос на отключение от дерева группы G, какие бы источники для неё не были. Отправляется в сторону RP. Так обрезается ветвь RPT.
Prune (S, G)
- запрос на отключение от дерева группы G, корнем которого является источник S. Отправляется в сторону источника. Так обрезается ветвь SPT.
Register
- специальное сообщение, внутри которого передаётся мультикаст на RP, пока не будет построено SPT от источника до RP. Передаётся юникастом от FHR на RP.
Register-Stop
- отправляется юникастом с RP на FHR, приказывая прекратить посылать мультикастовый трафик, инкапсулированный в Register.
- пакеты механизма BSR, которые позволяют выбрать маршрутизатор на роль BSR, а также передают информацию о существующих RP и группах.
Assert
- сообщение для выбора PIM Forwarder, чтобы в один сегмент не передавали трафик два маршрутизатора.
Candidate-RP-Advertisement
- сообщение, в котором RP отсылает на BSR информацию о том, какие группы он обслуживает.
RP-Reachable
- сообщение от RP, которым она уведомляет всех о своей доступности.
*Есть и другие типы сообщений в PIM, но это уже детали*
А давайте теперь попытаемся абстрагироваться от деталей протокола? И тогда становится очевидной его сложность.
1) Определение RP,
2) Регистрация источника на RP,
3) Переключение на дерево SPT.
Много состояний протокола, много записей в таблице мультикастовой маршрутизации. Можно ли что-то с этим сделать?
На сегодняшний день существует два диаметрально противоположных подхода к упрощению PIM: SSM и BIDIR PIM.
SSM
Всё, что мы описывали до сих пор - это ASM - Any Source Multicast . Клиентам безразлично, кто является источником трафика для группы - главное, что они его получают. Как вы помните в сообщении IGMPv2 Report запрашивается просто подключение к группе.SSM - Source Specific Multicast - альтернативный подход. В этом случае клиенты при подключении указывают группу и источник.
Что же это даёт? Ни много ни мало: возможность полностью избавиться от RP. LHR сразу знает адрес источника - нет необходимости слать Join на RP, маршрутизатор может сразу же отправить Join (S, G) в направлении источника и построить SPT.
Таким образом мы избавляемся от
- Поиска RP (протоколы Bootstrap и Auto-RP),
- Регистрации источника на мультикасте (а это лишнее время, двойное использование полосы пропускания и туннелирование)
- Переключения на SPT.
Ещё одна проблема, которая решается с помощью SSM - наличие нескольких источников. В ASM рекомендуется, чтобы адрес мультикастовой группы был уникален и только один источник вещал на него, поскольку в дереве RPT несколько потоков сольются, а клиент, получая два потока от разных источников, вероятно, не сможет их разобрать.
В SSM трафик от различных источников распространяется независимо, каждый по своему дереву SPT, и это уже становится не проблемой, а преимуществом - несколько серверов могут вещать одновременно. Если вдруг клиент начал фиксировать потери от основного источника, он может переключиться на резервный, даже не перезапрашивая его - он и так получал два потока.
Кроме того, возможный вектор атаки в сети с активированной мультикастовой маршрутизацией - подключение злоумышленником своего источника и генерирование большого объёма мультикастового трафика, который перегрузит сеть. В SSM такое практически исключено.
Для SSM выделен специальный диапазон IP-адресов: 232.0.0.0/8.
На маршрутизаторах для поддержки SSM включается режим PIM SSM.
Router(config)# ip pim ssm
IGMPv3 и MLDv2 поддерживают SSM в чистом виде.
При их использовании клиент может
- Запрашивать подключение к просто группе, без указания источников. То есть работает как типичный ASM.
- Запрашивать подключение к группе с определённым источником. Источников можно указать несколько - до каждого из них будет построено дерево.
- Запрашивать подключение к группе и указать список источников, от которых клиент не хотел бы получать трафик
IGMPv1/v2, MLDv1 не поддерживают SSM, но имеет место такое понятие, как SSM Mapping
. На ближайшем к клиенту маршрутизаторе (LHR) каждой группе ставится в соответствие адрес источника (или несколько). Поэтому если в сети есть клиенты, не поддерживающие IGMPv3/MLDv2, для них также будет построено SPT, а не RPT, благодаря тому, что адрес источника всё равно известен.
SSM Mapping может быть реализован как статической настройкой на LHR, так и посредством обращения к DNS-серверу.
Проблема SSM в том, что клиенты должны заранее знать адреса источников - никакой сигнализацией они им не сообщаются.
Поэтому SSM хорош в тех ситуациях, когда в сети определённый набор источников, их адреса заведомо известны и не будут меняться. А клиентские терминалы или приложения жёстко привязаны к ним.
Иными словами IPTV - весьма пригодная среда для внедрения SSM. Это хорошо описывает концепцию One-to-Many
- один источник, много получателей.
А что если в сети источники могут появляться спонтанно то там, то тут, вещать на одинаковые группы, быстро прекращать передачу и исчезать?
Например, такая ситуация возможна в сетевых играх или в ЦОД, где происходит репликация данных между различными серверами. Это концепция Many-to-Many
- много источников, много клиентов.
Как на это смотрит обычный PIM SM? Понятное дело, что инертный PIM SSM здесь совсем не подходит?
Вы только подумайте, какой хаос начнётся: бесконечные регистрации источников, перестроение деревьев, огромное количество записей (S, G) живущих по несколько минут из-за таймеров протокола.
На выручку идёт двунаправленный PIM (Bidirectional PIM, BIDIR PIM
). В отличие от SSM в нём напротив полностью отказываются от SPT и записей (S,G) - остаются только Shared Tree с корнем в RP.
И если в обычном PIM, дерево является односторонним - трафик всегда передаётся от источника вниз по SPT и от RP вниз по RPT - есть чёткое деление, где источник, где клиенты, то в двунаправленном от источника трафик к RP передаётся также вверх по Shared Tree - по тому же самому, по которому трафик течёт вниз к клиентам.
Это позволяет отказаться от регистрации источника на RP - трафик передаётся безусловно, без какой бы то ни было сигнализации и изменения состояний. Поскольку деревьев SPT нет вообще, то и SPT Switchover тоже не происходит.
Вот например:

Источник1
начал передавать в сеть трафик группы 224.2.2.4 одновременно с Источником2
. Потоки от них просто полились в сторону RP. Часть клиентов, которые находятся рядом начали получать трафик сразу, потому что на маршрутизаторах есть запись (*, G) (есть клиенты). Другая часть получает трафик по Shared Tree от RP. Причём получают они трафик от обоих источников одновременно.
То есть, если взять для примера умозрительную сетевую игру, Источник1
это первый игрок в стрелялке, который сделал выстрел, а Источник2
- это другой игрок, который сделал шаг в сторону. Информация об этих двух событиях распространилась по всей сети. И каждый
другой игрок (Получатель
) должен узнать об обоих этих событиях.
Если помните, то мы объяснили, зачем нужен процесс регистрации источника на RP - чтобы трафик не занимал канал, когда нет клиентов, то есть RP просто отказывался от него. Почему над этой проблемой мы не задумываемся сейчас? Причина проста: BIDIR PIM для ситуаций, когда источников много, но они вещают не постоянно, а периодически, относительно небольшими кусками данных. То есть канал от источника до RP не будет утилизироваться понапрасну.
Обратите внимание, что на изображении выше между R5 и R7 есть прямая линия, гораздо более короткая, чем путь через RP, но она не была использована, потому что Join идут в сторону RP согласно таблице маршрутизации, в которой данный путь не является оптимальным.
Выглядит довольно просто - нужно отправлять мультикастовые пакеты в направлении RP и всё, но есть один нюанс, который всё портит - RPF. В дереве RPT он требует, чтобы трафик приходил от RP и не иначе. А у нас он может приходить откуда угодно. Взять и отказаться от RPF мы, конечно, не можем - это единственный механизм, который позволяет избежать образования петель.
Поэтому в BIDIR PIM вводится понятие . В каждом сегменте сети, на каждой линии на эту роль выбирается тот маршрутизатор, чей маршрут до RP лучше.
В том числе это делается и на тех линиях, куда непосредственно подключены клиенты. В BIDIR PIM DF автоматически является DR.
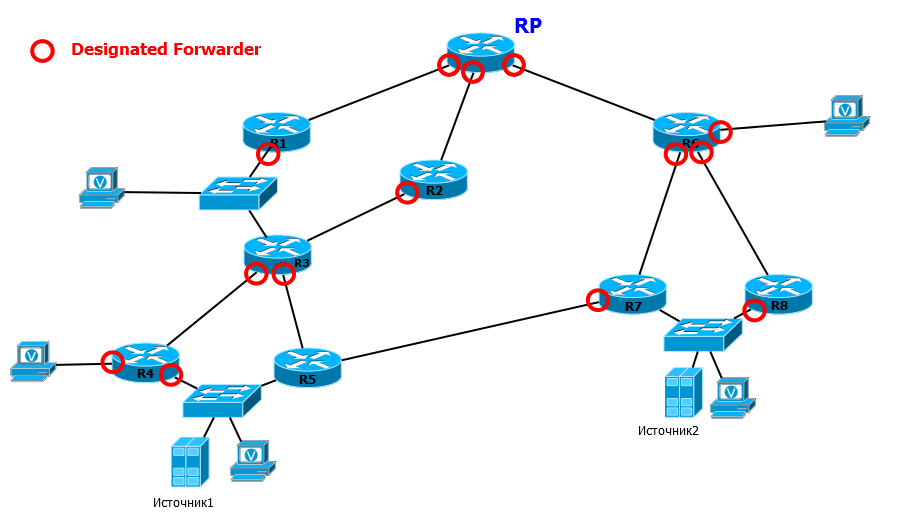
Список OIL формируется только из тех интерфейсов, на которых маршрутизатор был выбран на роль DF.
Правила довольно прозрачны:
- Если запрос PIM Join/Leave приходит на тот интерфейс, который в данном сегменте является DF, он передаётся в сторону RP по стандартным правилам.
Вот, например, R3. Если запросы пришли в DF интерфейсы, что помечены красным кругом, он их передаёт на RP (через R1 или R2, в зависимости от таблицы маршрутизации). - Если запрос PIM Join/Leave пришёл на не DF интерфейс, он будет проигнорирован.
Допустим, что клиент, находящийся между R1 и R3, решил подключиться и отправил IGMP Report. R1 получает его через интерфейс, где он выбран DF (помечен красным кругом), и мы возвращаемся к предыдущему сценарию. А R3 получает запрос на интерфейс, который не является DF. R3 видит, что тут он не лучший, и игнорирует запрос. - Если мультикастовый трафик пришёл на DF интерфейс, он будет отправлен в интерфейсы из списка OIL и в сторону RP.
Например, Источник1 начал передавать трафик. R4 получает его в свой DF интерфейс и передаёт его и в другой DF-интерфейс - в сторону клиента и в сторону RP, - это важно, потому что трафик должен попасть на RP и распространиться по всем получателям. Также поступает и R3 - одна копия в интерфейсы из списка OIL - то есть на R5, где он будет отброшен из-за проверки RPF, и другая - в сторону RP. - Если мультикастовый трафик пришёл на не DF интерфейс, он должен быть отправлен в интерфейсы из списка OIL, но не будет
отправлен в сторону RP.
К примеру, Источник2 начал вещать, трафик дошёл до RP и начал распространяться вниз по RPT. R3 получает трафик от R1, и он не передаст его на R2 - только вниз на R4 и на R5.
Таким образом DF гарантирует, что на RP в итоге будет отправлена только одна копия мультикастового пакета и образование петель исключено. При этом то общее дерево, в котором находится источник, естественно, получит этот трафик ещё до попадания на RP. RP, согласно обычным правилам разошлёт трафик во все порты OIL, кроме того, откуда пришёл трафик.
Кстати, нет нужды более и в сообщениях Assert, ведь DF выбирается в каждом сегменте. В отличие от DR он отвечает не только за отправку Join к RP, но и за передачу трафика в сегмент, то есть ситуация, когда два маршрутизатора передают в одну подсеть трафик, исключена в BIDIR PIM.
Пожалуй, последнее, что нужно сказать о двунаправленном PIM, это особенности работы RP. Если в PIM SM RP выполнял вполне конкретную функцию - регистрация источника, то в BIDIR PIM RP - это некая весьма условная точка, к которой стремится трафик с одной стороны и Join от клиентов с другой. Никто не должен выполнять декапсуляцию, запрашивать построение дерева SPT. Просто на каком-то маршрутизаторе вдруг трафик от источников начинает передаваться в Shared Tree. Почему я говорю «на каком-то»? Дело в том, что в BIDIR PIM RP - абстрактная точка, а не конкретный маршрутизатор, в качестве адреса RP вообще может выступать несуществующий IP-адрес - главное, чтобы он был маршрутизируемый (такая RP называется Phantom RP).
Все термины, касающиеся PIM, можно найти в глоссарии .
Мультикаст на канальном уровне
Итак, позади долгая трудовая неделя с недосыпами, переработками, тестами - вы успешно внедрили мультикаст и удовлетворили клиентов, директора и отдел продаж.Пятница - не самый плохой день, чтобы обозреть творение и позволить себе приятный отдых.
Но ваш послеобеденный сон вдруг потревожил звонок техподдержки, потом ещё один и ещё - ничего не работает, всё сломалось. Проверяете - идут потери, разрывы. Всё сходится на одном сегменте из нескольких коммутаторов.
Расчехлили SSH, проверили CPU, проверили утилизацию интерфейсов и волосы дыбом - загрузка почти под 100% на всех интерфейсах одного VLAN"а. Петля! Но откуда ей взяться, если никаких работ не проводилось? Минут 10 проверки и вы заметили, что на восходящем интерфейсе к ядру у вас много входящего трафика, а на всех нисходящих к клиентам - исходящего. Для петли это тоже характерно, но как-то подозрительно: внедрили мультикаст, никаких работ по переключению не делали и скачок только в одном направлении.
Проверили список мультикастовых групп на маршрутизаторе - а там подписка на все возможные каналы и все на один порт - естественно, тот, который ведёт в этот сегмент.
Дотошное расследование показало, что компьютер клиента заражён и рассылает IGMP Query на все мультикастовые адреса подряд.
Потери пакетов начались, потому что коммутаторам пришлось пропускать через себя огромный объём трафика. Это вызвало переполнение буферов интерфейсов.
Главный вопрос - почему трафик одного клиента начал копироваться во все порты?
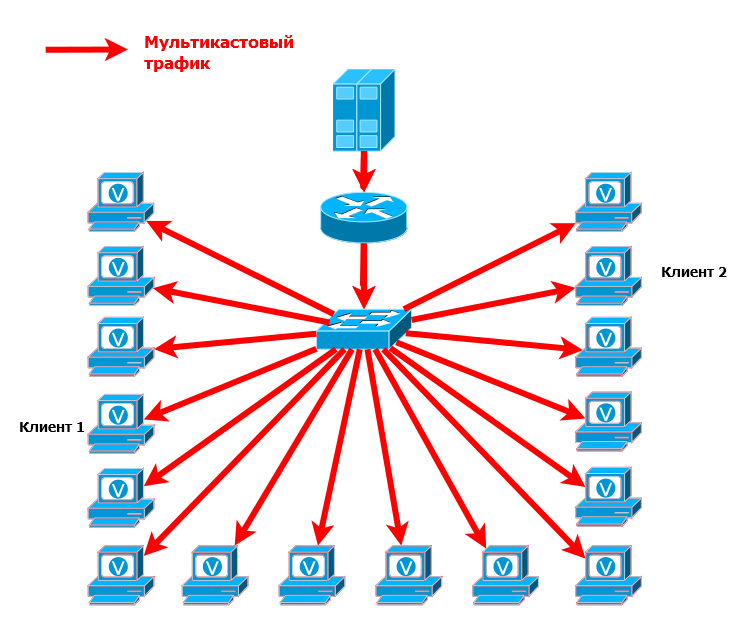
Причина этого кроется в природе мультикастовых MAC-адресов. Дело в том, пространство мультикастовых IP-адресов специальным образом отображается в пространство мультикастовых MAC-адресов. И загвоздка в том, что они никогда не будут использоваться в качестве MAC-адреса источника, а следовательно, не будут изучены коммутатором и занесены в таблицу MAC-адресов. А как поступает коммутатор с кадрами, адрес назначения которых не изучен? Он их рассылает во все порты. Что и произошло.
Это действие по умолчанию.
Мультикастовые MAC-адреса
Так какие же MAC-адреса получателей подставляются в заголовок Ethernet таких пакетов? Широковещательные? Нет. Существует специальный диапазон MAC-адресов, в которые отображаются мультикастовые IP-адреса.Эти специальные адреса начинаются так: 0x01005e и следующий 25-й бит должен быть 0 (попробуйте ответить, почему так ). Остальные 23 бита (напомню, всего их в МАС-адресе 48) переносятся из IP-адреса.
Здесь кроется некоторая не очень серьёзная, но проблема. Диапазон мультикастовых адресов определяется маской 224.0.0.0/4, это означает, что первые 4 бита зарезервированы: 1110, а оставшиеся 28 бит могут меняться. То есть у нас 2^28 мультикастовых IP-адресов и только 2^23 MAC-адресов - для отображения 1 в 1 не хватает 5 бит. Поэтому берутся просто последние 23 бита IP-адреса и один в один переносятся в MAC-адрес, остальные 5 отбрасываются.

Фактически это означает, что в один мультикастовый MAC-адрес будет отображаться 2^5=32 IP-адреса. Например, группы 224.0.0.1, 224.128.0.1, 225.0.0.1 и так до 239.128.0.1 все будут отображаться в один MAC-адрес 0100:5e00:0001.
Если взять в пример дамп потокового видео, то можно увидеть:
IP адрес - 224.2.2.4, MAC-адрес: 01:00:5E:02:02:04.
Есть также другие мультикастовые MAC-адреса, которые никак не относятся к IPv4-мультикаст (клик). Все они, кстати, характеризуются тем, что последний бит первого октета равен 1.
Естественно, ни на одной сетевой карте, не может быть настроен такой MAC-адрес, поэтому он никогда не будет в поле Source MAC Ethernet-кадра и никогда не попадёт в таблицу MAC-адресов. Значит такие кадры должны рассылаться как любой Unknown Unicast во все порты VLAN"а.
Всего, что мы рассматривали прежде, вполне достаточно для полноценной передачи любого мультикастового трафика от потокового видео до биржевых котировок. Но неужели мы в своём почти совершенном мире будем мирится с таким безобразием, как широковещательная передача того, что можно было бы передать избранным?
Вовсе нет. Специально для перфекционистов
придуман механизм IGMP-Snooping
.
IGMP-Snooping
Идея очень простая - коммутатор «слушает» проходящие через него IGMP-пакеты.Для каждой группы отдельно он ведёт таблицу восходящих и нисходящих портов.
Если с порта пришёл IGMP Report для группы, значит там клиент, коммутатор добавляет его в список нисходящих для этой группы.
Если с порта пришёл IGMP Query для группы, значит там маршрутизатор, коммутатор добавляет его в список восходящих.
Таким образом формируется таблица передачи мультикастового трафика на канальном уровне.
В итоге, когда сверху приходит мультикастовый поток, он копируется только в нисходящие интерфейсы. Если на 16-портовом коммутаторе только два клиента, только им и будет доставлен трафик.
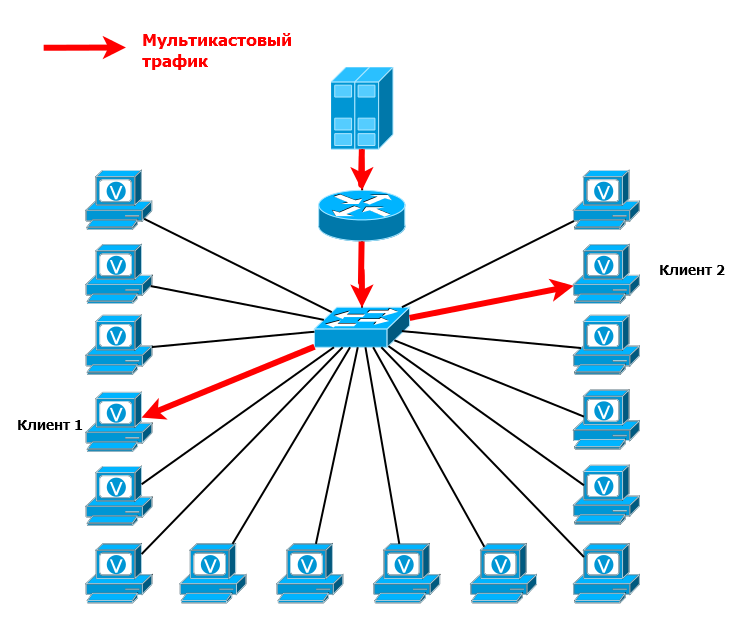
Гениальность этой идеи заканчивается тогда, когда мы задумываемся о её природе. Механизм предполагает, что коммутатор должен прослушивать трафик на 3-м уровне.
Впрочем, IGMP-Snooping ни в какое сравнение не идёт с NAT по степени игнорирования принципов сетевого взаимодействия. Тем более, кроме экономии в ресурсах, он несёт в себе массу менее очевидных возможностей. Да и в общем-то в современном мире, коммутатор, который умеет заглядывать внутрь IP - явление не исключительное.
Сервер 172.16.0.5 передает мультикаст трафик на группы 239.1.1.1, 239.2.2.2 и 239.0.0.x.
Настроить сеть таким образом, чтобы:
- клиент 1 не мог присоединиться к группе 239.2.2.2. Но при этом мог присоединиться к группе 239.0.0.x.
- клиент 2 не мог присоединиться к группе 239.1.1.1. Но при этом мог присоединиться к группе 239.0.0.x.
Напоследок нетривиальная задачка по мультикасту (авторы не мы, в ответах будет ссылка на оригинал).
Самая простая схема:

С одной стороны сервер-источник, с дугой - компьютер, который готов принимать трафик.
Адрес мультикастового потока вы можете устанавливать сами.
И соответственно, два вопроса:
1.
Что нужно сделать, чтобы компьютер мог получать поток и при этом не прибегать к мультикастовой маршрутизации?
2.
Допустим, вы вообще не знаете, что такое мультикаст и не можете его настраивать, как передать поток от сервера к компьютеру?
Задача легко ищется в поисковике, но попробуйте решить её сами.
За помощь в подготовке статьи спасибо …
За техническую поддержку спасибо Наташе Самойленко .
КДПВ нарисована Ниной Долгополовой - замечательным художником и другом проекта.
В пуле статей СДСМ ещё много интересного до окончания, поэтому не нужно хоронить цикл из-за долгого отсутствия выпуска - с каждой новой статьёй сложность значительно возрастает. Впереди почти весь MPLS, IPv6, QoS и дизайн сетей.
Как вы уже, наверно, заметили, у linkmeup появился новый проект - Глоссарий lookmeup (да, недалеко у нас ушла фантазия). Мы надеемся, что этот глоссарий станет самым полным справочником терминов в области связи, поэтому мы будем рады любой помощи в его заполнении. Пишите нам на [email protected]
Метки:
Добавить меткиIPTV - IP - television
Передача Unicast, Broadcast и Multicast трафика.
См. также:
Услуги IPTV
Основные протоколы IPTV
Типовая схема сети IPTV
Существует три основных метода передачи трафика в IP-сетях, это - Unicast, Broadcast и Multicast.
Понимание разницы между этими методами является очень важным для понимания преимуществ IP-телевидения и для практической организации трансляции видео в IP-сети.
Каждый из этих трех методов передачи использует различные типы назначения IP-адресов в соответствии с их задачами и имеется большая разница в степени их влияния на объем потребляемого трафика.
Unicast трафик (одноцелевая передача пакетов) используется прежде всего для сервисов «персонального» характера. Каждый абонент может запросить персональный видео-контент в произвольное, удобное ему время.
Unicast трафик направляется из одного источника к одному IP-адресу назначения. Этот адрес принадлежит в сети только одному единственному компьютеру или абонентскому STB как показано на рисунке ниже.
Число абонентов, которые могут получать unicast трафик одновременно, ограничено доступной в магистральной части сети шириной потока (скоростью потока). Для случая Gigabit Ethernet сети теоретическая максимальная ширина потока данных может приближаться к 1 Гб/сек за вычетом полосы, необходимой для передачи служебной информации и технологических запасов оборудования. Предположим, что в магистральной части сети мы можем для примера выделить не более половины полосы для сервисов, которым требуется unicast трафик. Легко подсчитать для случая 5Мб/сек на телевизионный канал MPEG2, что число одновременно получающих unicast трафик абонентов не может превышать 100.
Broadcast трафик (широковещательная передача пакетов) использует специальный IP-адрес, чтобы посылать один и тот же поток данных ко всем абонентам данной IP-сети. Например, такой IP-адрес может оканчиваться на 255, например 192.0.2.255, или иметь 255 во всех четырех полях (255.255.255.255).
Важно знать, что broadcastтрафик принимается всеми включенными компьютерами (или STB) в сети независимо от желания пользователя. По этой причине этот вид передачи используется в основном для служебной информации сетевого уровня или для передачи другой исключительно узкополосной информации. Разумеется, для передачи видео-данных broadcast трафик не используется. Пример передачи broadcastтрафика показан на рисунке ниже.

Multicast трафик (групповая передача пакетов) используется для передачи потокового видео, когда необходимо доставить видео-контент неограниченному числу абонентов, не перегружая сеть . Это наиболее часто используемый тип передачи данных в IPTV сетях, когда одну и ту же программу смотрят большое число абонентов.
Multicast трафик использует специальный класс IP-адресов назначения, например адреса в диапазоне 224.0.0.0 ….. 239.255.255.255. Это могут быть IP-адреса класса D.
В отличие от unicast трафика, multicast адреса не могут быть назначены индивидуальным компьютерам (или STB). Когда данные посылаются по одному из multicast IP-адресов, потенциальный приемник данных может принять решение принимать или не принимать их, то есть будет абонент смотреть этот канал или нет. Такой способ передачи означает, что головное оборудование IPTV оператора будет передавать один единственный поток данных по многим адресам назначения. В отличие от случая broadcast передачи, за абонентом остается выбор - принимать данные или нет.
Важно знать, что для реализации multicast передачи в IP-сети должны быть маршрутизаторы, поддерживающие multicast. Маршрутизаторы используют протокол IGMP для отслеживания текущего состояния групп рассылки (а именно, членство в той или иной группе того или иного конечного узла сети).
Основные правила работы протокола IGMP следующие:
Конечный узел сети посылает пакет IGMP типа report для обеспечения запуска процесса подключения к группе рассылки;
Узел не посылает никаких дополнительных пакетов при отключении от группы рассылки;
Маршрутизатор m ulticast через определенные временные интервалы посылает в сеть запросы IGMP. Эти запросы позволяют определить текущее состояние групп рассылки;
Узел посылает ответный пакет IGMP для каждой группы рассылки до тех пор, пока имеется хотя бы один клиент данной группы.

Загрузка магистральной части сети multicast трафиком зависит только от числа транслируемых в сети каналов. В ситуации с Gigabit Ethernet сетью, предположив, что половину магистрального трафика мы можем выделить под multicast передачу, мы получаем около 100 телевизионных MPEG-2 каналов, каждый имеющий скорость потока данных 5 Мб/сек.
Разумеется, в IPTV сети присутствуют одновременно все 3 вида трафика broadcast, multicast и unicast. Оператор, планируя оптимальную величину пропускной способности сети, должен учитывать разный механизм влияния разных технологий IP- адресации на объем трафика. Например, оператор должен ясно представлять себе, что предоставление услуги «видео на заказ» большому числу абонентов требует очень высокой пропускной способности магистральной сети. Одним из решений этой проблемы является децентрализация в сети видео-серверов. В этом случае центральный видео-сервер заменяется на несколько локальных серверов, разнесенных между собой и приближенных к периферийным сегментам многоуровневой иерархической архитектуры IP-сети.
Мультикастинг (multicasting) - это процесс одновременной доставки видео сигнала нескольким получателям. Все получатели имеют одинаковый сигнал в одно и то же время, как и в обычном телевидении. Можно сказать, что все ТВ вещание (спутниковое, эфирное, кабельное) соответствует концепции мультикастинга. Однако термин "мультикастинг" используется в основном в контексте с IP сетями.
Для более точного понимания термина мультикастинг, рассмотрим для начала процесс юникастинг (unicasting). При юникастинге каждый видеопоток предназначен только для одного получателя. Если несколько абонентов хотят смотреть одну и ту же программу (фильм), то источнику сигнала необходимо создать соответствующее число юникастовых потоков от источника до каждого получателя.
Говоря про юникастовое вещание в IP сетях, мы говорим о традиционном пути, по которому проходят пакеты видеопотока от источника до получателя. Источник видеопотока подготавливает каждый пакет с указанием IP адреса получателя и пакеты проходят по сети с незначительными модификациями, заключающимися в основном в изменении поля TTL (Time To Live). Соответственно, когда один и тот же видеопоток запрашивают несколько получателей, источник должен подготовить соответствующее количество IP пакетов со своими IP адресами получателей. При увеличении количества юникастовых запросов возрастает загрузка источника, что в конечном итоге приведет к невозможности создавать новые индивидуальные IP пакеты. Например, если мы хотим организовать вещание для 20-ти пользователей и передавать видеопоток со скоростью 2.5 Mbps, то нам необходимо обеспечить сетевое соединение источника с пропускной способностью по крайней мере 50 Mbps.
Основным преимуществом юникастового вещания является то, что абонент может посмотреть именно то, что он хочет в данный момент времени. Обычно системы юникастового вещания дополняются функциями обеспечивающими остановку, паузу и перемотку при просмотре. Системы юникастового вещания не требуют специального оборудования, как для мультикастовых приложений. Данные системы могут работать даже на базе Internet.
К недостаткам юникастовых систем можно отнести необходимость наличия большого процессорного и сетевого ресурса на источнике видеопотоков. Также необходима достаточная полоса пропускания между источником и получателем, даже в случае, когда, например, 50 получателей, находящихся в одном здании захотят одновременно смотреть каждый свою программу - в данном случае полоса пропускания сети должна быть по крайней мере в 50 раз больше, чем ширина канала, необходимая для передачи одного видеопотока. Источник видеосигнала должен следить за состоянием каждого сетевого устройства, пославшего запрос на просмотр, а это тоже отнимает ресурсы.
При мультикасте один видео поток могут получить одновременно все абоненты сети. Используя специальные протоколы, сеть направляет копии данного потока каждому получателю. Процесс создания копий видеопотока происходит внутри самой сети, не затрагивая ресурсы источника видеопотока. Копии видеопотока доставляются до каждого получателя, только если от него поступал соответствующий запрос.
Напомним, что IP сети поддерживают функцию, названную бродкастинг (broadcasting - широковещательные пакеты, при котором IP пакет доставляется каждому сетевому устройству. Каждое устройство, получившее такой широковещательный пакет, должно его обработать соответствующим образом. Широковещательные пакеты не должны использоваться для организации видео вещания, не смотря на то, что пакеты небольшие, они могут "забить" все сетевые устройства сети, даже если они данным устройством не запрашивались. В то же время большинство маршрутизаторов сетей сконфигурированы на запрет пересылки широковещательных пакетов из одной сети в другую, что также ограничивает возможность использования бродкастовых пакетов для организации видео вещания. IP мультикастинг в чистом виде подразумевает пересылку пакетов только тем устройствам, которые выполнили соответствующий запрос, тем самым присоединившись (joining) к мультикасту.
Специальные сетевые протоколы позволяют сети организовать доставку одинаковых пакетов множеству получателей. Это достигается путем присвоения пакету специального адреса из диапазона адресов, зарезервированных под мултикастинг. Эти же протоколы позволяют новым пользоваться присоединяться к выбранному мультикасту.
Большинство сетевых устройств (таких как маршрутизаторы) имеют возможности обработки мультикастовых пакетов, но по умолчанию в большинстве сетей данная функция заблокирована, ввиду значительного увеличения нагрузки по обработки данных пакетов. Например, предположим, что на 12-ть портов маршрутизатора поступили запросы на просмотр мультикастового вещания. Эти порты должны быть соединены либо с конечным получателем, либо с другим маршрутизатором, если запросы пришли из других подсетей. Мультикасту необходимо создать 12 копий мультикастовых пакетов и послать каждую копию на свой порт, откуда поступили запросы. В тоже время, маршрутизатор должен постоянно следить за каждым портом на предмет поступления новых запросов и/или окончания просмотра на одном из портов. Данная функция поддерживается соответствующим программным обеспечением маршрутизатора.
Отметим еще раз, что мультикаст является однонаправленной системой, по аналогии с эфирным вещанием. Не существует механизма по собиранию и отправки запросов от конечных получателей к источнику, влияющих на процесс мультикаста.
Одним из удобств мультикаста является простота процесса подключения и отключения для абонента в любой момент времени. Данная функция целиком возложена на сетевые устройства, и от источника видеопотока не требуется никаких действий при добавлении/удалении нового получателя мультикастового потока. Рассмотрим этот процесс подробнее.
В мультикастовых системах все получатели могут смотреть одновременно один и тот же видеопоток. Вот почему, когда новый пользователь захочет смотреть этот поток, он должен присоединиться (join) к мультикастовому потоку. Источник мультикастового потока отвечает за периодическую рассылку доступности видеопотока для пользователей сети (за это отвечают SAP пакеты). Пользователи, которые хотят присоединиться к мультикастовому потоку должны сперва получить и проанализировать SAP пакеты, в которых содержится информация как сконфигурирован выбранный мультикастовый поток, после чего пользователь может выполнить подсоединение к потоку.
Когда маршрутизатор получил запрос от пользователя на присоединение к мультикасту, он должен выполнить несколько действий. Сперва маршрутизатор должен определить, формировал ли уже он нужные пакеты для другого пользователя. Если да, то ему остается только создать копию этих пакетов и послать их новому пользователю. Если же нет, то маршрутизатор должен сделать соответствующий запрос устройству, находящемуся ближе к источнику видеопотока (выше по сетевой иерархии). После получения ответа от него, маршрутизатор должен направить полученные мультикастовые пакеты получателю. В данном случае (при мультикасте) в сети присутствуют только копии одного видеопотока, что уменьшает занимаемую полосу пропускания всей сети по сравнению с юникастовыми системами.
Процесс отсоединения пользователя от мультикастового потока так же влияет на эффективность функционирования сети. В данном случае пользовательское устройство должно информировать маршрутизатор о намерении отсоединиться от мультикастового потока. Получив такой сигнал, маршрутизатор прекращает посылку данного мультикаста на соответствующий порт и в случае, если больше нет пользователей, которые принимают данный поток, маршрутизатор сообщает вышестоящему маршрутизатору, чтобы тот в свою очередь также прекратил посылку мультикаст пакетов на соответствующий порт. Данный процесс очень важен, т.к. без него сеть может очень быстро заполниться никому не нужными мултикаст потоками.
Напомним преимущества мультикаста: только одна копия видеопотока вещается в сети, что уменьшает требования к полосе пропускания, причем видеопоток могут получать многие абоненты сети; процесс создания копий пакетов видеопотока возложен на сетевые устройства, что разгружает источник видеопотока; простота развертывания системы вещания по IP сетям; при мультикасте возможно использование видеосигнала более высокого качества за счет меньшего сжатия.
К недостаткам мультикаста можно отнести то, что в данный момент времени абоненту можно смотреть только то, что вещается источником видеосигнала, и на этот процесс повлиять нельзя. Сетевое оборудование должно поддерживать мультикастинг и должно быть сконфигурировано соответствующим образом. В большинстве случаев мультикаст возможно организовать только в частных сетях. Мультикаст увеличивает нагрузку на маршрутизаторы сети. Контроль со стороны оператора за подключением к мультикасту может оказаться сложной задачей. Достаточно сложной является задача интеграции сети общего пользования и частной сети, в которой развернут мультикастинг. Некоторые файрволы (шлюзы, NAT) блокируют мультикастовые потоки.
Архитектура мультикаст систем
Мультикастинг в IP сетях основан на IGMP (Internet Group Management Protocol). Данный протокол был разработан в 80-х гг и подвергался нескольким доработкам. Наибольшее распространение получил протокол IGMP Version 2 (V2). Последней версией является V3, но она не так распространена.
Назначением IGMP является предоставление информации для маршрутизатора о мультикастовых потоках/пакетах. Маршрутизаторы выполняют большую работу по обработке мультикастовых пакетов: пересылка и замена мультикаст пакетов для всех получателей, которым эти пакеты предназначены; правильная пересылка пакетов между портами; копирование входных мультикаст пакетов на несколько выходных портов в случае такой необходимости.
SAP (Session Announcement Protocol) используется для периодического информирования мультикаст абонентов о программах (видео и звуковых потоках), которые присутствуют в мультикаст потоках сети. SAP напоминает телегид-сервис, присутствующий в некоторых кабельных сетях, когда в передаваемом списке присутствуют названия программ и номера их каналов. По аналогии, SAP используется для информирования о каждом мультикаст потоке, включая название программы и настройки для подключения к нему.
Возможно наиболее важной информацией из SAP является мультикастовый адрес мультикаст потока. Получив его, абонентское устройство может сформировать требуемый запрос на подключение к выбранному мультикаст потоку. Один мультикаст источник может формировать множество мультикаст потоков, сведения о которых могут отражаться в SAP. Например, видеокодер может предлагать две версии одной программы: высокого качества и низкого качества (соответственно, первая для пользователей с быстрым подключением к сети, вторая - для пользователей с низкоскоростным подключением к сети провайдера услуг) и три звуковых потока (музыка, радио). В данном случае каждый пользователь может настроиться на поток, соответствующий возможностям сетевого соединения абонента.
По умолчанию, SAP соединение происходит на групповом адресе 224.2.127.254 порт 9875. Специальное программное обеспечение на абонентских устройствах преобразует информацию полученную из SAP в список, удобный к просмотру пользователем. После выбора пользователем интересующей программы абонентское устройство (мультимедиа плеер) выполняет команду на подсоедиение (joining) к соответствующему мультикаст потоку.
"Присоединение" и "отключение" являются ключевыми понятиями в мультикаст системах. Если пользовательское устройство формирует запрос на получение мультикаст потока, то все сетевые устройства между получателем и источником должны быть переконфигурированы на доставку соответствующего мультикаст потока. Обратимся к простому примеру:
Пользовательское устройство UD1 первым посылает команду "join" на просмотр доступного мультикаст потока. Маршрутизатор R3, являющийся ближайшим к UD1, определяет, что до этого момента он не получал данный мультикаст поток, поэтому он делает запрос на вышестоящий маршрутизатор R2, переправляющий в свою очередь запрос на R1. Маршрутизатор R1 начинает посылку мультикаст пакетов на R2. Тот - далее на R3, после чего пакеты попадают на UD1. Когда второй пользователь UD2 посылает запрос на получение мультикаст потока, цепочка запросов повторяется: UD2->R5->R4->R2. Т.к. R2 в этот момент времени уже пересылает нужный мультикаст поток другому получателю, то ему остается только сделать копию пакетов и направить их на R4 и далее до UD2 через R5. В следующий момент подключается третий пользователь UD3, подключенный напрямую к R4. Т.к. этому маршрутизатору не нужно инициировать новый поток, то он начинает просто копировать уже существующий.
Рассмотрим процесс отключения. Если пользователь UD1 решил прекратить просмотр, то он посылает команду "leave" (покинуть) на R3. R3 прекращает посылку мультикаст пакетов на UD1. Затем R3 должен проверить необходимость посылки данного мультикаст потока на другие порты и после подтверждения, что в данном потоке больше никто не нуждается, R3 посылает команду "leave" на R2. R2, в свою очередь, видя, что данный поток нужен другим получателям, просто прекращает "тиражирование" мультикаст пакетов на порт, к которому подключен R3. При этом, пользователи UD2 и UD3 продолжают получать мультикаст поток.
Рассмотренный пример показал некоторую сложность процесса подключения и отключения от мультикаст потока. Это своеобразная плата за достигаемую эффективность сети. Необходимые для этого операции с IGMP могут создать значительную нагрузку на сеть, поэтому сеть, предназначенная для мультикаста, должна иметь соответствующие по производительности маршрутизаторы.
Напомним основные моменты:
- между двумя точками сети пересылается только одна копия каждого из мультикаст потоков;
- не имеет значения сколько получателей данного потока существует после маршрутизатора вниз по иерархии сети.
Важно отметить, что команда "leave" была введена только в версии IGMP V2. В версии 1 маршрутизатор должен был сам посылать запросы на состояние устройства, "слушающего" мультикаст. Если ответа от устройства не поступало, то маршрутизатор должен был самостоятельно прекращать передачу мультикаст пакетов. Если маршрутизатор выполнял такие запросы слишком часто, то это приводило к тому, что канал связи "забивался" такими запросами. Представьте себе ситуацию, если такой метод использовался бы для систем "Видео по запросу по DSL": соединение с устройством может быть быстро "заполнено" мультикаст потоком, которые пользователь больше не смотрит, но при этом абонентское устройство от сети не отсоединено. В версии IGMP V2 данная проблема решается посылкой команды "leave" после прекращения просмотра данного мультикаст потока, что освобождает канал для других приложений и/или мультикаст потоков.
Требования к ресурсам системы
Ввиду того, что большинство IP сетей развернуты с отключенной поддержкой мультикастинга, следует понимать, что произойдет, если эту поддержку включить. Рассмотрим изменения, затрагивающие маршрутизаторы, сервера и полосу пропускания сети.
Переконфигурирование маршрутизаторов
Невозможно описать все тонкости настройки тысяч моделей сетевого оборудования, поэтому перечислим основные функции, которые должны поддерживать маршрутизаторы:
- Принимать, дублировать и пересылать далее SAP пакеты, которые посылаются каждому устройству, желающему принимать мультикаст вещание. Несмотря на то, что данные пакеты поступают не очень часто, они должны быть соответствующим образом обработаны и пересланы на все порты маршрутизатора, с которых возможны запросы на просмотр мультикаста.
- Обработчик IGMP пакетов должен определять, когда абонентское устройство делает запрос на подсоединение (join) к мультикасту и запрос на отключение (leave) от мультикаста. Напомним, что при поступлении запроса на подсоединение, маршрутизатор, в случае если этот запрос является первым для данного мультикаста, должен сформировать соответствующий запрос вышестоящему по иерархии маршрутизатору. Соответствующие действия должны быть предприняты и в случае отключения от мультикаста.
- Тиражирование мультикаст пакетов для обеспечения ими всех портов, с которых поступают запросы. Это может сильно увеличить нагрузку на маршрутизатор, особенно, если данная функция выполняется маршрутизатором программно, что характерно для устаревших маршрутизаторов. Для мультикаст вещания видеопотоков от маршрутизатора потребуется выполнение тиражирования нескольких сотен пакетов в секунду.
Долгое время системные администраторы неохотно включали поддержку мультикаста в своих сетях. Поэтому наверняка потребуется замена/переконфигурирование большинства маршрутизаторов по всей сети, а это повлечет и временные и материальные затраты.
Для серверов увеличение загрузки в случае развертывания мультикаст вещания будет незначительным по сравнению с юникастовым вещанием. Для юникаста серверу необходимо создавать отдельный поток для каждого принимающего устройства. Сервера для мультикаст вещания будут иметь значительно меньшую нагрузку и для каждой программы необходимо будет создать только один мультикастовый поток - копии для каждого приемного устройства создадут маршрутизаторы. Поэтому для мультикастовых систем требования к серверу могут быть менее жесткими, чем к серверам для систем "Видео по запросу".
Анализ полосы пропускания
В мультикастовых системах только одна копия видео потока пересылается между маршрутизаторами, и как следствие, канал менее загружен по сравнению с юникаст системами. Рассмотрим пример: сеть на 100 пользователей. 16 из них хотят смотреть одну и ту же программу. Предположим, что в сети 4 маршрутизатора, соединенных каждый с каждым (на техническом жаргоне - "full mesh"). Предположим, что видео источник соединен с одним из маршрутизаторов (А), а пользователи равномерно распределены между 4-мя маршрутизаторами (по 4 пользователя на каждый маршрутизатор). Посмотрим, что будет с нашим каналом.
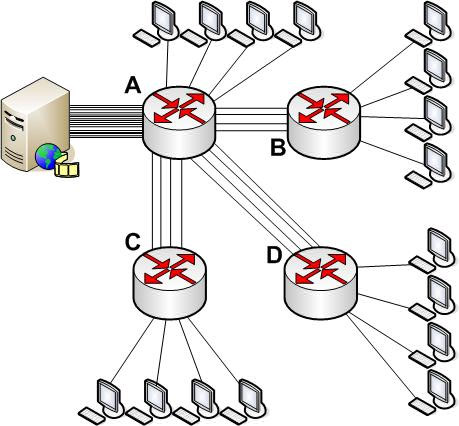
В юникастовой системе (см. рис.) источник видео потока должен создать по одной копии потока для каждого из 16-ти пользователей - всего 16 потоков, посылаемых до маршрутизатора А. Маршрутизатор А должен принять каждый из них и переслать по назначению: четыре потока - локальным пользователям данного маршрутизатора и по четыре потока каждому из оставшихся маршрутизаторов В, С и D.
В мультикастовой системе источнику видео потока необходимо создать только одну копию видео потока (все пользователи хотят смотреть одну и ту же программу), а маршрутизатор А должен создать всего семь копий пакетов для видеопотока, 4 из которых направятся локальным пользователям.
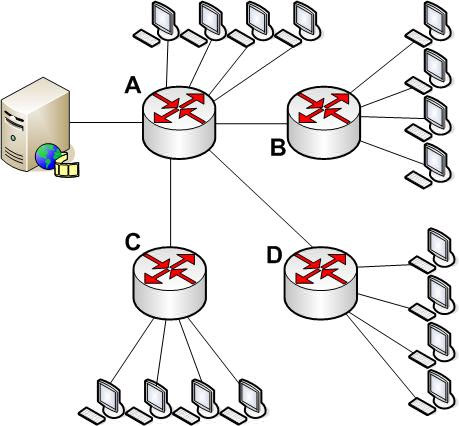
Другие три потока направляются на оставшиеся маршрутизаторы В, С и D. Каждый из этих маршрутизаторов должен создать по 4 копии пакетов видеопотока.
Большое отличие этих двух реализаций заметно в необходимой полосе пропускания между источником видео потока и маршрутизатором А. Во втором случае в качестве каналов связи могут использоваться более медленные соединения, что позволит значительно сэкономить в случае использования арендованных каналов.
В сетях IP существует 3 основных способа передачи данных : Unicast, Broadcast, Multicast.
Unicast (юникаст) – процесс отправки пакета от одного хоста к другому хосту.
Multicast (мультикаст) – процесс отправки пакета от одного хоста к некоторой ограниченной группе хостов.
Broadcast (бродкаст) – процесс отправки пакета от одного хоста ко всем хостам в сети.
Эти 3 типа передачи данных используются для различных целей, давайте рассмотрим более подробно.
Unicast
Тип передачи данных Unicast (индивидуальный) используется для обычной передачи данных от хоста к хосту. Способ Unicast работает в клиент-серверных и пиринговых (peer-to-peer, от равного к равному) сетях.
В unicast пакетах в качестве IP адреса назначения используется конкретный IP адрес устройства, для которого этот пакет предназначен. IP адрес конкретного устройства состоит из порции адреса сети (в которой находится это устройство) и порции адреса хоста (порции, определяющей это конкретное устойчиво в его сети). Это все приводит к возможности маршрутизации unicast пакетов по всей сети.
Multicast и broadcast пакеты, в отличие от unicast пакетов, имеют свои собственные специальные (зарезервированные) IP адреса для использования их в заголовке пакетов в качестве пункта назначения. Из-за этого, broadcast пакеты в основном ограничены пределами локальной сети. Multicast трафик также может быть ограничен границами локальной сети, но с другой стороны также может и маршрутизироваться между сетями.
В IP сетях unicast адрес является адресом, то есть адресом конечного устройства (например, компьютера). Для типа передачи данных unicast, адреса хостов назначаются двум конечным устройствам и используются (эти адреса) как IP адрес источника и IP адрес получателя.
В течение процесса инкапсуляции передающий хост размещает свой IP адрес в заголовок unicast пакета в виде адреса источника, а ИП адрес принимающего хоста размещается в заголовке в виде адреса получателя. Используя эти два IP адреса, пакеты unicast могут передаваться через всю сеть (т.е. через все подсети).
Multicast
Тип передачи multicast разрабатывался для сбережения пропускной способности в IP сетях. Такой тип уменьшает трафик, позволяя хостам отправить один пакет выбранной группе хостов. Для достижения нескольких хостов назначения используя передачу данных unicast, хосту источнику было бы необходимо отправить каждому хосту назначения один и тот же пакет. С типом передачи данных multicast, хост источник может отправить всего один пакет, который может достичь тысячи хостов получателей.
Примеры multicast передачи данных:
- видео и аудио рассылка
- обмен информацией о маршрутах, используемый в маршрутизируемых протоколах.
- распространение программного обеспечения
- ленты новостей
Multicast клиенты
Хосты, которые хотят получить определенные multicast данные, называются multicast клиентами. Multicast клиенты используют сервисы инициированные (начатые) клиентскими программами для рассылки multicast данных группам.
Каждая multicast группа представляет собой один multicast IP адрес назначения. Когда хост рассылает данные для multicast группы, хост помещает multicast IP адрес в заголовок пакета (в раздел пункта назначения).
Для multicast групп выделен специальный блок IP адресов, от 224.0.0.0 до 239.255.255.255.
Broadcast (Широковещание)
Из-за того, что тип передачи broadcast используется для отправки пакетов ко всем хостам в сети, пакеты использую специальный broadcast IP адрес. Когда хост получает пакет, в заголовке которого в качестве адреса получателя указан broadcast адрес, он обрабатывает пакет так, как будто это unicast пакет.
Когда хосту необходимо передать какую-то информацию всем хостам в сети используется способ передачи данных broadcast. Еще когда адрес специальных сервисов (служб) или устройств заранее неизвестен, то для обнаружения также используется broadcast (широковещание).
Примеры, когда используется broadcast передача данных:
- создание карты принадлежности адресов верхнего уровня к нижним (например, какой IP адрес на конкретном устройстве со своим MAC адресом)
- запрос адреса (в качестве примера можно взять протокол ARP)
- протоколы маршрутизации обмениваются информацией о маршрутах (RIP, EIGRP, OSPF)
Когда хосту нужна информация, он отправляет запрос на широковещательный адрес. Все остальные хосты в сети получат и обработают этот запрос. Один или несколько хостов вложат запрашиваемую информацию и ответят на запрос. В качестве типа передачи данных, отвечающие на запрос будут использовать unicast.
Подобным образом, когда хосту необходимо отправить информацию всем хостам в сети, он создаёт широковещательный пакет с его информацией и передаёт его в сеть.
В отличие от unicast передачи, где пакеты могут быть маршрутизированы через всю сеть, broadcast пакеты, как правило, ограничиваются локальной сетью. Это ограничение зависит от настройки маршрутизатора, который ограничивает сеть и следит за типом широковещания (broadcast).
Существует два типа broadcast передачи данных: направленное широковещание и ограниченное широковещание.
Направленный broadcast (направленное широковещание)
Направленный broadcast отправляется всем хостам какой-то конкретной сети. Этот тип широковещания удобно использовать для отправки broadcast трафика всем хостам за пределами локальной сети.
Например, хост хочет отправить пакет всем хостам в сети 172.16.5.0/24, но сам хост находится в другой сети. В данном случае хост-отправитель вложит в заголовок пакета в качестве адреса пункта назначения broadcast адрес 172.16.5.255. Хотя маршрутизаторы должны ограничивать (не передавать) направленный широковещательный трафик, их можно настроить на разрешение передачи broadcast трафика.
Ограниченный broadcast (ограниченное широковещание)
Ограниченный broadcast используется для передачи данных всем хостам в локальной сети. В такие пакеты в качестве пункта назначения вставляется IP адрес 255.255.255.255. Маршрутизаторы такой широковещательный трафик не передают. Пакеты, переданные ограниченным broadcast будут распространяться только в локальной сети. По этой причине локальные сети IP также называют широковещательным доменом (broadcast domain). Маршрутизаторы образуют границу для широковещательного домена. Без границы пакеты бы распространялись по всей сети, каждому хосту, уменьшая быстродействие сетевых устройств и забивая пропускную способность каналов связи.
Приведу пример ограниченного broadcast: хост находится внутри сети 172.16.5.0/24 и хочет передать пакет всем хостам в его сети. Используя в качестве пункта назначения IP адрес 255.255.255.255, он отправляет широковещательный пакет. Этот пакет примут и обработают все хосты только в этой локальной сети (172.16.5.0/24).