Избавляемся от назойливой captcha во Вконтакте. Самые удобные сервисы для распознания капчи
Эти приемы я буду демонстрировать на подопытной капче. В качестве подопытной я выбрал капчу некоего Rafontes на которую я набрел когда искал материалы для предыдущей статьи .
Пример сгенерированной капчи:
Фон мне пришлось использовать другой, так как автор не выложил оригинальный (или я не нашел), но это не повлияет на результат.
Препроцесс
В результате этого действия мы получим масимально обрезанный участок монохромного изображения с текстом.
В первую очередь нам надо отделить фон от текста . Анализируем картинку и код генерации изображения. Налицо первые ошибки:
- Используется один цвет для всего теста с кодом
- Цвет для текста генерируется в диапазоне rand(0, 200), 0, rand(0, 200), для R G B соответственно (достаточно выделить цвета только в этом диапазоне)
- Фон с большим количеством разных цветов (не сможет повлиять на статистику самого часто используемого цвета)
Теперь на основе этих фактов анализируем цвет каждого пикселя во всем изображении и выделяем самый часто-используемый. Получился 8C0074
(в hex-виде). Задаем от него небольшую погрешность и выделяем этот цвет и немного похожие на него с учетом погрешности. Все выделенные закрашиваем черным, остальные белым. Получается такая картинка: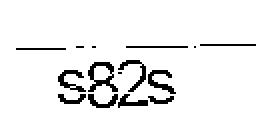
Как видите, мы получили текст, практически без искажений. Правда осталась одна линия, но у нас хитрый алгоритм обрезки (о нем ниже), на который эта линия повлиять не сможет.
Теперь выделяем участок с кодом
.
Так как наш текст это самое темное пятно, то и пытаемся алгоритмически найти это пятно. Сначала определяем границы по горизонтали:
Теперь определяем границы по вертикали: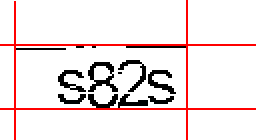
Линия осталась тут потому что то тот участок до сих пор воспринимается функцией как очень темный участок. Но теперь на основе этих границ уточняем их по второму кругу, по горизонтали:

А почему теперь эта линия убралась спросите вы? Потому что теперь анализировалось меньше «столбцов пикселей» и при анализе алгоритмом выявилось что в данном участке слишком много столбцов с одним черным пикселем, а следовательно это шум. Теперь уточняем границу по вертикали:

Так как область определения стала меньше то, теперь тот та линия что была шумом стала недостаточно темным пятном и была удаленна совсем. Вот мы и получили участок с текстом. Конечно этот алгоритм иногда не совсем верно выделяет нужную область. Но по моим тестам число НЕверных определений не превышает 5%, чем собственно можно пренебречь.
Сегментация
Теперь наша задача разбить полученное изображение на отдельные участки с символами.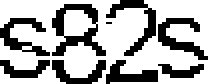
Конечно можно расчитывать, искать границы символов, и тд. Но если опять проанализировать код генерации, то можно найти еще одну ошибку.
- Отступ между каждым символом всегда равен 15 пикселям
Конечно иногда из за размера символов они выходять за рамки пятнадцати пикселей, тогда приходится откусывать от соседнего символа еще один-два пикселя. Но это не критично. Вообщем разбиваем картинку:
Теперь как мы видим вокруг некоторых символов есть пустая область. А нам все таки нужен именно сам символ. Применяем функцию обрезки для каждого символа, и полученные изображения вписываем в прямоугольники размером 17×27:
Именно такие изображения по отдельности будут подаваться на распознавание.
Распознавание
Распознавание мы будет производить БЕЗ всяких новомодных нейронных сетей. Почему? Решающую роль сыграло то что, нет ни одной достойной библиотеки под винду. Пользоваться будем обычным распознаванием по маскам символов.
Для этого мы, имея доступ к исходным кодам, нагенерируем кучу черно-белых картинок для каждого символа с разными углами поворотов (от двух до четырех градусов), и разными размерами шрифта (от 20pt до 30pt). Каждую полученную картинку, как вы догадались, вписываем в прямоугольник размером 17×27. Каждое полученное изображение называется маской.
Для каждой буквы я нагенерировал по 10-15 масок. Впринципе этого достаточно, но если увеличить количество масок, то можно увеличить процент распознавания.
Вообщем все изображения подающиеся на вход, сравниваются с масками, и алгоритм определяет какая маска больше всего соответствует нашему изображению, на основе этого делая вывод о том какой символ написан на картинке.
Результаты
Для теста я получил с помощью генерации картинки и ее разбиения на символы 200 зашумленных символов. И програмно запустил тест. И внимание!
Итог: Удачных: 172 Ошибок: 28 Процент: 86%
То есть каждый символ на капче будет распознан успешно с вероятностью в 86%
!
Немного математики. Посчитаем процент вероятности успешного распознавания капчи:
Для 4-символьных капч: 0.86^4=54%
Для 5-символьных капч: 0.86^5=47%
В среднем каждая вторая капча будет успешно распознанна.
Если учесть что на каждую капчу приходится около 1 секунды, а 2 секунды в среднем будет приходится на успешное распознавание. То это очень отличный результат.
Исходники
Скрипт сам генерирует, и сам же распознает капчу. Пример работы скрипта на картинке приведенной в качестве примера автором капчи:
(Картинка кликабельна)
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Капча - тест на человечность, используемый для защиты ресурса от спама и роботов. Но честным людям она мешает, например, проверить позиции сайта. Поэтому ее взламывают с помощью инструментов, основанных на слабых местах технологии. Сегодня расскажем, как противостоять капче.
Кому нужно обходить капчу
Ее обходят не только спамеры для создания большого количества новых ящиков, комментариев на форумах, страниц в социальных сетях для дальнейшего распространения спама. Защиту нужно обходить и честным компаниям для получения результатов в автоматическом режиме. Например, владельцу сайта для проверки позиций в поисковой системе или ресурсам, занимающимся автоматическим сбором тематической информации.
Грубый перебор всех вариантов
Еще когда создавались капчи, вопросы и ответы придумывали вручную и их было ограниченное количество. Это значит, что побыв некоторое время на сайте и собрав все возможные ответы, их можно было собрать в базу данных и использовать для взлома.
Как защититься: генерировать варианты автоматически, чтобы их нельзя было предугадать или собрать все возможные ответы. Сейчас это уже не вызывает проблем, буквы и символы собираются автоматически, как и арифметические примеры.
Получение имени поля
Как взломать: достаточно взять имя поля капчи из кода и с помощью программы перехватывать его значение, если оно никогда не меняется.
Как защититься: использовать динамическое имя поля, то есть каждый раз изменяемое. Оно обязательно должно быть зашифровано, чтобы другие программы не могли его считать и получить ответ. Ключ к расшифровке будет находиться на сервере, получить его нельзя без доступа к серверному скрипту.
Например, капча хранится в поле Captcha. Тогда очень просто создать программу, которая будет читать значение из него. Подобрать имя можно вручную или использовать базы наиболее популярных, которые хранятся в открытом доступе. Однако, если имя постоянно называется по-иному и не просто словом, а например, последовательностью букв «fghtn» или «qpvbn», то отследить это будет сложнее. И наиболее безопасный вариант: зашифровать эту последовательность.
Обход капчи с помощью OCR
OCR - технология распознавания текста для преобразования в цифровой вид, доступный для редактирования. Пример популярной программы - ABBYY FineReader. Из бесплатных, но менее известных: ocropy , . Все что нужно: настроить необходимые параметры и загрузить картинку.
Метод также используется для распознавания капчи онлайн. Программа считывает картинку и вводит значения в поле. Как работает алгоритм внутри:
- Изображение с буквами или цифрами очищается от шумов для четкого распознавания символов.
- Оно разбивается на отдельные фрагменты с одним знаком.
- Каждый символ сравнивается с оригиналами, заранее загруженными в базу.
- В конце выводится итоговое значение.
Для защиты от взлома с помощью OCR, создаются специальные капчи с большим количеством шума, непонятными символами. Знаки могут быть так искажены, что даже человек с первого раза не найдет правильный ответ.
Для обхода нужно найти разные оригиналы, чтобы в большинстве случаев система смогла правильно определить символ. Нужны разные шрифты и кодировки.
Как защищают капчу от OCR:
- накладывают на изображение шумы того же цвета, что и основные символы;
- добавляет лишние знаки и отдельно текстом просят ввести лишь некоторые из них, а не все подряд (как сделает это робот);
- буквы и цифры располагают на разном уровне;
- используют уникальное, нестандартное оформление.
Применяемые меры препятствуют автоматическому вводу символов.
Написанные скрипты
Этот способ не является полноценным для обхода. Его используют как вспомогательный, что система OCR могла максимально четко опознать символы.
Программист пишет с использованием специальных библиотек скрипт, который:
- предварительно очищает картинку от шума, лишних знаков, фона;
- работает с цветами, чтобы они не мешали процессу распознавания;
- обрезает ненужные области, оставляя только знаки;
- выравнивает текст.
Использование прокси
Прокси-сервисы позволяют пользователю находится в сети анонимно. Таким образом, он скрывает свой настоящий IP-адрес, местоположение и другую информацию о себе. Отследить его становится невозможным без специального оборудования, поэтому блокировка по IP не совсем удачна.
Для обхода нужно иметь доступ к базам прокси-сервисов. Они могут быть как бесплатными, там и распространяться коммерчески на закрытых сайтах. Основной алгоритм состоит в постоянной смене IP. В этом случае сайт может и не выдавать капчу, потому что одни и те же действия совершаются разными адресами.
Этот способ обхода был придуман одним из первых.
Как с помощью Google взломать его же капчу
В 2017 году один разработчик выложил в своем блоге способ обхода reCaptcha от Google, детально описав весь процесс.
Этот вид капчи отличается от остальных тем, что пользователю показывается изображение, деленное на несколько частей. Его просят указать все фрагменты, на которых изображен предмет X. Он отмечает их галочками, и если все верно, ответ засчитывается. У нее есть также аудио-аналог, когда робот называет цифры, и текстовый с тестом, который решит может только человек.
Основной алгоритм был следующим. Нужно было скачать аудиофайл и переконвертировать его в формат WAV, который распознает Google Speech Recognition API. В результате он получал цифровую последовательность, которую загружал на сайт и получал готовую капчу. Если попадался именно текстовый вариант, то страница просто обновлялась до тех пор, пока не будет именно аудиоформат.
- Ориентируйтесь на соотношение цены и объема работы. Для распознавания нескольких тысяч капч в день выбирают более дорогие варианты программ, способных обрабатывать много информации. Если цели меньше, подойдут онлайн-сервисы, большинство которых бесплатны.
- При выборе бесплатного сервиса, проверяйте на наличие дополнительных ограничений. В идеале, их не должно быть. Например, лимиты на распознавание или триал-время.
- Если вы останавливаетесь на бирже с исполнителями, проверьте ее репутацию, прочитав отзывы на различных источниках. Некоторые разводят не только исполнителей, но и заказчиков.
- Скачивайте программы с проверенных источников. Сейчас на рынке становится меньше программ, их вытесняют серверы, которые не нужно устанавливать на компьютер и работают они круглосуточно.
Программы и сервисы для распознавания капчи
Из программ по распознаванию капч можно выделяется CapMonster 2 . Она основана на технологии OCR. Стоимость зависит от количества поток - 1, 5 и 20, и соответственно, 37$, 57$, 97$.
Основные возможности:
- высокая производительность - миллионы капч за сутки;
- большая база поддерживаемых капч;
- обучение новым типам капч как со стороны разработчиков, так и со стороны пользователя;
- покупка дополнительных поток для профессионального тарифа.
Вернуть программу можно в течение 14 дней после покупки, а абонентская плата вносится ежегодно.
Биржи с исполнителями - универсальное решение. Во-первых, капчи распознаются за естественное время. Роботы работают быстрее человека в несколько раз, поэтому сайт, использующих защиту, увидит по статистике взлом. Но если капчу вводит человек, то аналитика будет в пределах нормы.
Во-вторых, доступны все виды капч, которые можно распознать человеком. Это не гарантирует 100% обхода, потому что все могут ошибаться.
В-третьих, это дешево. Обычно до 50 рублей за 1.000 штук, но за сложные может быть и 150.
Примеры бирж с исполнителями:
Уточняйте правила работы с сервисами в правилах пользовательского соглашения.
Подводим итоги
Программисты могут допускать ошибки из-за невнимательности, из-за недостаточного тестирования либо просто из-за незнания. Хакеры пользуются изъянами в безопасности и находят способы разрушить систему. Создаются специальные программы для автоматического распознавания капчи и сервисы онлайн, которые работают и платно, и бесплатно.
Есть разные способы для обхода CAPTCHA, которыми защищены сайты. Во-первых, существуют специальные сервисы, которые используют дешевый ручной труд и буквально за $1 предлагают решить 1000 капч. В качестве альтернативы можно попробовать написать интеллектуальную систему, которая по определенным алгоритмам будет сама выполнять распознавание. Последнее теперь можно реализовать с помощью специальной утилиты.
Решить CAPTCHA
Распознавание CAPTCHA - задача чаще всего нетривиальная. На изображение необходимо накладывать массу различных фильтров, чтобы убрать искажения и помехи, которыми разработчики желают укрепить стойкость защиты. Зачастую приходится реализовывать обучаемую систему на основе нейронные сетей (это, к слову, не так сложно, как может показаться), чтобы добиться приемлемого результата по автоматизированному решению капч. Чтобы понять, о чем я говорю, лучше поднять архив и прочитать замечательные статьи «Взлом CAPTCHA: теория и практика. Разбираемся, как ломают капчи» и «Подсмотрим и распознаем. Взлом Captcha-фильтров» из #135 и #126 номеров соответственно. Сегодня же я хочу рассказать тебе о разработке TesserCap, которую автор называет универсальной решалкой CAPTCHA. Любопытная штука, как ни крути.
Первый взгляд на TesserCap
Что сделал автор программы? Он посмотрел, как обычно подходят к проблеме автоматизированного решения CAPTCHA и попробовал обобщить этот опыт в одном инструменте. Автор заметил, что для удаления шумов с изображения, то есть решения самой сложной задачи при распознавании капч, чаще всего применяются одни и те же фильтры. Получается, что если реализовать удобный инструмент, позволяющий без сложных математических преобразований накладывать фильтры на изображения, и совместить его с OCR-системой для распознавания текста, то можно получить вполне работоспособную программу. Это, собственно, и сделал Гурсев Сингх Калра из компании McAfee. Зачем это было нужно? Автор утилиты решил таким образом проверить, насколько безопасны капчи крупных ресурсов. Для тестирования были выбраны те интернет-сайты, которые являются самыми посещаемыми по версии известного сервиса статистики . Кандидатами на участие в тестировании стали такие монстры, как Wikipedia, eBay, а также провайдер капч reCaptcha.
Если рассматривать в общих чертах принцип функционирования программы, то он достаточно прост. Исходная капча поступает в систему предварительной обработки изображений, очищающей капчу от всяких шумов и искажений и по конвейеру передающей полученное изображение OCR-системе, которая старается распознать текст на нем. TesserCap имеет интерактивный графический интерфейс и обладает следующими свойствами:
- Имеет универсальную систему предварительной обработки изображений, которую можно настроить для каждой отдельной капчи.
- Включает в себя систему распознавания Tesseract , которая извлекает текст из предварительно проанализированного и подготовленного CAPTCHA-изображения.
- Поддерживает использование различных кодировок в системе распознавания.
Думаю, общий смысл понятен, поэтому предлагаю посмотреть, как это выглядит. Универсальность утилиты не могла не привести к усложнению ее интерфейса, поэтому окно программы может ввести в небольшой ступор. Так что, перед тем как переходить непосредственно к распознаванию капч, предлагаю разобраться с ее интерфейсом и заложенным функционалом.
 Предварительная обработка изображений и извлечение
Предварительная обработка изображений и извлечениетекста из капчи
About
Мы не могли не сказать хотя бы пары слов об авторе замечательной утилиты TesserCap. Его зовут Гурсев Сингх Калра. Он работает главным консультантом в подразделении профессиональных услуг Foundstone, которое входит в состав компании McAfee. Гурсев выступал на таких конференциях, как ToorCon, NullCon и ClubHack. Является автором инструментов TesserCap и SSLSmart. Помимо этого, разработал несколько инструментов для внутренних нужд компании. Любимые языки программирования - Ruby, Ruby on Rails и C#. Подразделение профессиональных услуг Foundstone®, в котором он трудится, предлагает организациям экспертные услуги и обучение, обеспечивает постоянную и действенную защиту их активов от самых серьезных угроз. Команда подразделения профессиональных услуг состоит из признанных экспертов в области безопасности и разработчиков, имеющих богатый опыт сотрудничества с международными корпорациями и государственными
Интерфейс. Вкладка Main
После запуска программы перед нами предстает окно с тремя вкладками: Main, Options, Image Preprocessing. Основная вкладка содержит элементы управления, которые используются для запуска и остановки теста CAPTCHA-изображения, формирования статистики теста (сколько отгадано, а сколько нет), навигации и выбора изображения для предварительной обработки. В поле для ввода URL-адреса (элемент управления № 1) должен быть указан точный URL-адрес, который веб-приложение использует для извлечения капч. URL-адрес можно получить следующим образом: кликнуть в правой части CAPTCHA-изображения, скопировать или просмотреть код страницы и извлечь URL-адрес из атрибута src тега изображения ..сайт/common/rateit/captcha.asp?. Рядом со строкой адреса находится элемент, задающий количество капч, которые нужно загрузить для тестирования. Так как приложение может одновременно показывать только 12 изображений, в нем предусмотрены элементы управления для постраничного пролистывания загруженных капч. Таким образом, при масштабном тестировании мы сможем пролистывать загруженные капчи и просматривать результаты их распознавания. Кнопки Start и Stop запускают и останавливают тестирование соответственно. После тестирования нужно оценить результаты распознавания изображений, отметив каждый из них как корректный или некорректный. Ну и последняя, наиболее значимая функция служит для передачи любого изображения в систему предварительной обработки, в которой задается фильтр, удаляющий с изображения шумы и искажения. Чтобы передать картинку в систему предварительной обработки, надо щелкнуть на требуемом изображении правой кнопкой мыши и в контекстном меню выбрать пункт Send To Image Preprocessor.
Интерфейс. Вкладка Options
Вкладка опций содержит различные элементы управления для конфигурирования TesserCap. Здесь можно выбрать OCR-систему, задать параметры веб-прокси, включить переадресацию и предварительную обработку изображений, добавить пользовательские HTTP-заголовки, а также указать диапазон символов для системы распознавания: цифры, буквы в нижнем регистре, буквы в верхнем регистре, специальные символы.
Теперь о каждой опции поподробней. Прежде всего, можно выбрать OCR-систему. По умолчанию доступна только одна - Tesseract-ORC, так что заморачиваться с выбором тут не придется. Еще одна очень интересная возможность программы - выбор диапазона символов. Возьмем, например, капчу с сайт - видно, что она не содержит ни одной буквы, а состоит только из цифр. Так зачем нам лишние символы, которые только увеличат вероятность некорректного распознавания?. Но что если выбрать Upper Case? Сможет ли программа распознать капчу, состоящую из заглавных букв любого языка? Нет, не сможет. Программа берет список символов, используемых для распознавания, из конфигурационных файлов, находящихся в \Program Files\Foundstone Free Tools\TesserCap 1.0\tessdata\configs. Поясню на примере: если мы выбрали опции Numerics и Lower Case, то программа обратится к файлу lowernumeric, начинающемуся с параметра tesseditchar whitelist. За ним следует список символов, которые будут использоваться для решения капчи. По умолчанию в файлах содержатся только буквы латинского алфавита, так что для распознавания кириллицы надо заменить или дополнить список символов.
Теперь немного о том, для чего нужно поле Http Request Headers. Например, на некоторых веб-сайтах нужно залогиниться, для того чтобы увидеть капчу. Чтобы TesserCap смогла получить доступ к капче, программе необходимо передать в запросе HTTP такие заголовки, как Accept, Cookie и Referrer и т. д. Используя веб-прокси (Fiddler, Burp, Charles, WebScarab, Paros и т. д.), можно перехватить посылаемые заголовки запроса и ввести их в поле ввода Http Request Headers. Еще одна опция, которая наверняка пригодится, - это Follow Redirects. Дело в том, что TesserCap по умолчанию не следует переадресации. Если тестовый URL-адрес должен следовать переадресации для получения изображения, нужно выбрать эту опцию.
Ну и осталась последняя опция, включающая/отключающая механизм предварительной обработки изображений, который мы рассмотрим далее. По умолчанию предварительная обработка изображений отключена. Пользователи сначала настраивают фильтры предварительной обработки изображений согласно тестируемым CAPTCHA-изображениям и затем активируют этот модуль. Все CAPTCHA-изображения, загружаемые после включения опции Enable Image Preprocessing, проходят предварительную обработку и уже затем передаются в OCR-систему Tesseract для извлечения текста.
Интерфейс. Вкладка Image Preprocessing
Ну вот мы и добрались до самой интересной вкладки. Именно тут настраиваются фильтры для удаления с капч различных шумов и размытий, которые стараются максимально усложнить задачу системе распознавания. Процесс настройки универсального фильтра предельно прост и состоит из девяти этапов. На каждом этапе предварительной обработки изображения его изменения отображаются. Кроме того, на странице имеется компонент проверки, который позволяет оценить правильность распознавания капчи при наложенном фильтре. Рассмотрим подробно каждый этап.
Этап 1. Инверсия цвета
На данном этапе инвертируются цвета пикселей для CAPTCHA-изображений. Код, представленный ниже, демонстрирует, как это происходит:
For(each pixel in CAPTCHA) { if (invertRed is true) new red = 255 – current red if (invertBlue is true) new blue = 255 – current blue if (invertGreen is true) new green = 255 – current green }
Инверсия одного или нескольких цветов часто открывает новые возможности для проверки тестируемого CAPTCHA-изображения.
Этап 2. Изменение цвета
На данном шаге можно изменить цветовые компоненты для всех пикселей изображения. Каждое числовое поле может содержать 257 (от 1 до 255) возможных значений. Для RGB-компонентов каждого пикселя в зависимости от значения в поле выполняются следующие действия:
- Если значение равно -1, соответствующий цветовой компонент не меняется.
- Если значение не равно -1, все найденные компоненты указанного цвета (красный, зеленый или синий) меняются в соответствии с введенным в поля значением. Значение 0 удаляет компонент, значение 255 устанавливает его максимальную интенсивность и т. д.
Этап 3. Градация серого (Шкала яркости)
На третьем этапе все изображения конвертируются в изображения в градациях серого. Это единственный обязательный этап преобразования изображений, который нельзя пропустить. В зависимости от выбранной кнопки выполняется одно из следующих действий, связанных с цветовой составляющей каждого пикселя:
- Average -> (Red + Green + Blue)/3.
- Human -> (0.21 * Red + 0.71 * Green + 0.07 * Blue).
- Average of minimum and maximum color components -> (Minimum (Red + Green + Blue) + Maximum (Red + Green + Blue))/2.
- Minimum -> Minimum (Red + Green + Blue).
- Maximum -> Maximum (Red + Green + Blue).
В зависимости от интенсивности и распределения цветовой составляющей CAPTCHA любой из этих фильтров может улучшить извлекаемое изображение для дальнейшей обработки.

Этап 4. Сглаживание и резкость
Чтобы усложнить извлечение текста из CAPTCHA-изображений, в них добавляют шум в форме однопиксельных или многопиксельных точек, посторонних линий и пространственных искажений. При сглаживании изображения возрастает случайный шум, для устранения которого потом используются фильтры Bucket или Cutoff. В числовом поле Passes следует указать, сколько раз нужно применить соответствующую маску изображения перед переходом на следующий этап. Давай рассмотрим компоненты фильтра для сглаживания и повышения резкости. Доступны два типа масок изображения:
- Фиксированные маски. По умолчанию TesserCap имеет шесть наиболее популярных масок изображения. Эти маски могут сглаживать изображение или повышать резкость (преобразование Лапласа). Изменения отображаются сразу же после выбора маски с помощью соответствующих кнопок.
- Пользовательские маски изображения. Пользователь также может настроить пользовательские маски обработки изображений, вводя значения в числовые поля и нажимая кнопку Save Mask. если сумма коэффициентов в этих окошках меньше нуля, выдается ошибка и маска не применяется. При выборе фиксированной маски кнопку Save Mask использовать не требуется.
Этап 5. Вводим оттенки серого
На этом этапе обработки изображения его пиксели могут быть окрашены в широкий диапазон оттенков серого. Этот фильтр отображает распределение градаций серого в 20 бакетах (bucket)/диапазонах. Процент пикселей, окрашенных в оттенки серого в диапазоне от 0 до 12, указан в бакете (bucket) 0, процент пикселей, окрашенных в оттенки серого в диапазоне от 13 до 25, - в бакете (bucket) 1 и т. д. Пользователь может выбрать одно из следующих действий для каждого диапазона значений, соответствующих оттенкам серого:
- Оставить без изменения (Leave As Is).
- Заменить белым (White).
- Заменить черным (Black).
Благодаря этим опциям можно контролировать различные диапазоны оттенков серого, а также сокращать/удалять шум путем, меняя оттенки серого в сторону белого или черного.
Этап 6. Настройка отсечения (cutoff)
Этот фильтр строит график зависимости значения уровня серого от частоты встречаемости и предлагает выбрать отсечение. Принцип работы отсекающего фильтра показан ниже в псевдокоде:
If (pixel’s grayscale value <= Cutoff) pixel grayscale value = (0 OR 255) -> в зависимости, от того какая опция выбрана (<= или => : Set Every Pixel with value <=/=> Threshold to 0. Remaining to 255)
График показывает подробное распределение пикселей CAPTCHA по цветам и помогает удалить помехи с помощью отсечения значений уровня серого.
Этап 7: Обтесывание (chopping)
После применения сглаживающего, отсекающего, bucket- и других фильтров CAPTCHA-изображения все еще могут быть зашумлены однопиксельными или многопиксельными точками, посторонними линиями и пространственными искажениями. Принцип работы фильтра обтесывания заключается в следующем: если количество смежных пикселей, окрашенных в данный оттенок серого, меньше величины в числовом поле, фильтр обтесывания присваивает им значение 0 (черный) или 255 (белый) по выбору пользователя. При этом CAPTCHA анализируется как в горизонтальном, так и в вертикальном направлении.
Этап 8: Изменение ширины границы
Как утверждает автор утилиты, в ходе первоначальных исследований и разработки TesserCap он неоднократно отмечал, что, когда CAPTCHA-изображения имеют толстую граничную линию и ее цвет отличается от основного фона CAPTCHA, некоторые системы OCR не могут распознать текст. Данный фильтр предназначен для обработки граничных линий и их изменения. Граничные линии с шириной, которая указана в числовом поле, окрашиваются в черный или белый по выбору пользователя.
Этап 9: Инверсия серого оттенка
Этот фильтр проходит каждый пиксель и заменяет его значение уровня серого новым, как показано ниже в псевдокоде. Инверсия серого проводится для подгонки изображения под цветовые настройки OCR-системы.
For(each pixel in CAPTCHA) new grayscale value = 255 – current grayscale value
Этап 10: Проверка распознавания капчи
Цель данного этапа - передать предварительно обработанное CAPTCHA-изображение OCR-системе для распознавания. Кнопка Solve берет изображение после фильтра инверсии серого, отправляет в OCR-систему для извлечения текста и отображает возвращенный текст в графическом интерфейсе. Если распознанный текст совпадает с текстом на капче, значит, мы правильно задали фильтр для предварительной обработки. Теперь можно перейти на вкладку опций и включить опцию предварительной обработки (Enable Image Preprocessing) для обработки всех последующих загруженных капч.
Распознаем капчи
Ну что ж, пожалуй, мы рассмотрели все опции этой утилиты, и теперь неплохо было бы протестировать какую-нибудь капчу на прочность..
 Результат анализа капчи сайт с предварительной
Результат анализа капчи сайт с предварительнойобработкой изображений. Судя по результатам, фильтр
подобрать не удалось
Итак, запускаем утилиту и идем на сайт журнала. Видим список свежих новостей, заходим в первую попавшуюся и пролистываем до места, где можно оставить свой комментарий. Ага, коммент так просто не добавить (еще бы, а то бы давно уже всё заспамили) - нужно вводить капчу. Ну что ж, проверим, можно ли это автоматизировать. Копируем URL картинки и вставляем его в адресную строку TesserCap. Указываем, что нужно загрузить 12 капч, и нажимаем Start. Программа послушно загрузила 12 картинок и попыталась их распознать. К сожалению, все капчи оказались либо не распознаны, о чем свидетельствует надпись -Failed- под ними, либо распознаны неправильно. В общем, неудивительно, так как посторонние шумы и искажения не были удалены. Этим мы сейчас и займемся. Жмем правой кнопкой мыши на одну из 12 загруженных картинок и отправляем ее в систему предварительной обработки (Send To Image Preprocessor). Внимательно рассмотрев все 12 капч, видим, что они содержат только цифры, поэтому идем на вкладку опций и указываем, что распознавать нужно только цифры (Character Set = Numerics). Теперь можно переходить на вкладку Image Preprocessing для настройки фильтров. Сразу скажу, что поигравшись с первыми тремя фильтрами («Инверсия цвета», «Изменение цвета», «Градация серого») я не увидел никакого положительного эффекта, поэтому оставил там всё по дефолту. Я выбрал маску Smooth Mask 2 и установил количество проходов равным одному. Фильтр Grayscale buckets я пропустил и перешел сразу к настройке отсечения. Выбрал значение 154 и указал, что те пиксели, которых меньше, нужно установить в 0, а те, которых больше, в 255. Чтобы избавиться от оставшихся точек, включил chopping и изменил ширину границы до 10. Последний фильтр включать не было смысла, поэтому я сразу нажал на Solve.
На капче у меня было число 714945, но программа распознала его как 711435. Это, как видишь, совершенно неверно. В конечном итоге, как я ни бился, нормально распознать капчу у меня так и не получилось. Пришлось экспериментировать с pastebin.com, которые без проблем удалось распознать. Но если ты окажешься усидчивее и терпеливее и сумеешь получить корректное распознавание капч с сайт, то сразу заходи на вкладку опций и включай предварительную обработку изображений (Enable Image Preprocessing). Затем переходи на Main и, кликнув на Start, загружай свежую порцию капч, которые теперь будут предварительно обрабатываться твоим фильтром. После того, как программа отработает, отметь корректно/некорректно распознанные капчи (кнопки Mark as Correct/Mark as InCorrect). С этого момента можно посматривать сводную статистику по распознаванию с помощью Show Statistics. В общем-то, это своеобразный отчет о защищенности той или иной CAPTCHA. Если стоит вопрос о выборе того или другого решения, то с помощью TesserCap вполне можно провести свое собственное тестирование.
Результат проверки CAPTCHA на популярных сайтах
Веб-сайт и доля распознанных капч:
- Wikipedia > 20–30 %
- Ebay > 20–30 %
- reddit.com > 20–30 %
- CNBC > 50 %
- foodnetwork.com > 80–90 %
- dailymail.co.uk > 30 %
- megaupload.com > 80 %
- pastebin.com > 70–80 %
- cavenue.com > 80 %
Заключение
CAPTCHA-изображения являются одним из самых эффективных механизмов по защите веб-приложений от автоматизированного заполнения форм. Однако слабые капчи смогут защитить от случайных роботов и не устоят перед целенаправленными попытками их решить. Как и криптографические алгоритмы, CAPTCHA-изображения, тщательно протестированные и обеспечивающие высокий уровень безопасности, являются самым лучшим способом защиты. На основе статистики, которую привел автор программы, я выбрал для своих проектов reCaptcha и буду рекомендовать ее всем своим друзьям - она оказалось самой стойкой из протестированных. В любом случае не стоит забывать, что в Сети есть немало сервисов, которые предлагают полуавтоматизированное решение CAPTCHA. Через специальный API ты передаешь сервису изображение, а тот через непродолжительное время возвращает решение. Решает капчу реальный человек (например, из Китая), получая за это свою копеечку. Тут уже никакой защиты нет. 🙂
Наверное, многим пользователям интернета, хоть когда-нибудь, но нужно было ввести капчу, это обычный способ определения автоматической программой робот вы или человек. Так вот, случается так, что необходимо определение целой кучи картинок, а времени на ввод каждой из них терять ну никак не хочется.
- Критерии выбора программы для распознавания капчей
- Перечень бесплатных программ для обхода капч и их отличия
Если вы столкнулись с такой проблемой, решение есть - онлайн-сервисы, которые помогут вам не тратить лишнее время на ввод капч. Ни для кого не секрет, что при усовершенствовании программ распознавания пользователя (определение человек это или робот), также усовершенствуются и программы , которые могут взламывать защиту и распознавать капчу автоматически. Существуют дорогие программы типа OCR, которые отлично справляются с поставленной задачей. Но, согласитесь, кому хочется тратить кучу денег для того чтобы распознать картинки. Поскольку безвыходных ситуаций не бывает, решение находится и в этом случае - бесплатный онлайн-сервис, причем, стоит заметить, что он такой не один. Ниже рассмотрим подробнее имеющиеся варианты.
Критерии выбора программы для распознавания капчей
Если вы занимаетесь какой-либо деятельностью, которая требует постоянного распознавания кодов, тогда есть смысл приобрести дорогой вариант программы, в случае, когда осуществлять рассматриваемый процесс приходится не так часто, не стоит выбрасывать крупную сумму денежных средств, для такого дела бесплатный сервис, воспользоваться которым не составит труда.
Таких сервисов десятки, и пользователь имеет возможность воспользоваться любым из них, так что выбрать будет из чего.
Для того чтобы сделать правильный выбор из такого многообразия программ, необходимо учитывать следующие аспекты:
- в первую очередь, выбранный вами сервис в обязательном порядке должен быть полностью бесплатным. Этот критерий самый важный, так что смотрите, чтобы никаких ограничений на этот счет не было;
- выбранный сервис должен уметь «угадывать» текст на русском языке, без этого критерия, у вас вряд ли получится сделать процесс ввода капч автоматическим;
- количество капчи, которые можно определить автоматически, должно быть неограниченным.
Смотрите видео - Как включить распознавание капчи через antigate, rucaptcha, captcha24, captchabot на DelphiXE5
Перечень бесплатных программ для обхода капч и их отличия
Итак, начнем рассмотрение имеющихся бесплатных вариантов, на очереди онлайн сервис Google Диск. Для того чтобы воспользоваться рассматриваемой программой, необходимо будет зарегистрироваться, такой ход событий ожидает пользователя практически во всех сервисах аналогичного назначения. В том случае. Если вы когда-либо уже создавали. К примеру, блог на blogspot, тогда регистрация вам в данном случае не понадобится. Здесь возможно автоматический ввод такой капчи: PDF, JPG, PNG и GIF. Необходимо отметить, что объем файлов для распознания должен быть не больше 2-3 Мб.
Онлайн-сервис OCR Convert. Здесь регистрации пользователю не понадобится. Форматы капчи , которые поддерживаются, следующие: JPEG, GIF, BMP. Нужно отметить, что сохраненные файлы имеют вид URL ссылки, расширение которых в формате TXT. Здесь пользователь сможет одновременно поставить на загрузку 5-7 документов.
Сервис i2OCR. Для того чтобы распознать капчи, необходимо для начала зарегистрироваться. Одновременно загруженных файлов и документов может быть не больше 10. Пользоваться данным сервисом удобно и просто. Форматы, которые он распознает следующие: GIF, PBM, PGM, PPM.
Доброго времени суток, дамы и господа.
Сервисы автоматического распознавания капчи могут помочь в самых разнообразных ситуациях. Например, они значительно облегчают работу программ для сбора семантического ядра – Кей Коллектор, СловоЁб и т. д., приложений для проверки текста на уникальность и рерайт – AntiPlagiarism.
При больших объемах того же текста или запросов, вы можете столкнуться с тем, что запрос на ввод капчи будет вылетать каждые 10 секунд. Не очень удобно, правда? Антикапча лишает вас необходимости вводить эти самые цифры и буквы вручную. Это делают другие люди, которые зарабатывают на их разгадывании. Вам нужно лишь оплатить услуги сервисов, которые предлагают автоввод капчи.
Большая часть программ, которая сотрудничает с онлайн-сервисами (Вордстат, Гугл Аналитика и т. д.), требует постоянного ввода капчи. Таким онлайн-проектам не выгодно, чтобы с ними работали боты, поэтому они всеми силами пытаются с этим бороться.
Но как быть простым вебмастерам, которые решили собрать семантику или спарсить данные с сервисов аналитики? Делать вручную? Не очень разумное решение, тем более, что сейчас полным-полно программ для расшифровки капчи, причем бесплатных.
Капчу разгадывают реальные люди, получая за это вознаграждение. Они работают в специальном окне, скрипт которого перенаправляет капчу из вашей программы прямо к ним. При правильном вводе происходит автозаполнение. Ваше приложение работает без перебоев и вам больше не надо беспокоиться по этому поводу.
Сайты распознавания капчи предлагают своим работникам фиксированную ставку за капчу. Вам, как клиентам, нужно внести определенную сумму на баланс. Потихоньку она будет убывать.
Сервисы автоматического ввода не требуют больших вложений. 300 – 400 рублей на несколько месяцев, а то и полгода, будет вполне достаточно. Но это зависит еще и от количества использования.
С помощью специальных кодов или данных от аккаунта на таком сайте, вы сможете интегрировать нужное приложение с сервисом.
Список онлайн-сервисов для распознавания капчи
Если вы тоже хотите, чтобы ваши утилиты работали в режиме “авто”, то вам нужно ознакомиться с этим списком. Здесь я представлю на ваш суд наиболее популярные сайты, которые помогут избавиться от нужды вводить капчу вручную.
RuCaptcha
RuCaptcha – популярный проект, который решает проблему работы со многими приложениями. Цены здесь повыше, чем в остальных, на 10 рублей, но зато качество и скорость работы этому соответствует.
Умеет работать со всеми типами проверки на робота, поэтому вы можете не беспокоиться, если вдруг выскочит новая капча от Гугла, где нужно выбрать какие-то дорожные знаки и т. д., пользователи РуКапчи легко с этим справятся за пару минут.
В остальном сервис похож на остальные. Легкое API, интеграция почти с любой программой и, что самое главное, – большое количество исполнителей. Многие люди знают, в свободное время, помогая тем самым простым пользователям.
2Captcha
Англоязычный ресурс, очень похож на РуКапчу. Средняя цена за 1 000 разгадываний – полбакса. Исходя из этого, можно прийти к выводу, что цены, как на рынке СНГ.
2Captcha отлично работает с Гуглом. Как правило, там англоговорящие работники, которые специализируются чисто на гугловских капчах. С русскими вариантами (от того же Яндекса) может возникнуть проблема. Но, думаю, свой исполнитель найдется и там.
Anti Captcha
Anti Captcha – современный сервис (бывший Антигейт), который предоставляет услуги по автоматическому разгадыванию символов. Проект отличается максимально упрощенным API, большим количеством исполнителей и низкими ценами.
Сравнительное дешевые расценки и качественное исполнение услуги точно не оставит вас равнодушными. Сайт известен в Рунете, а потому среднее время разгадывания символов составляет всего 10 – 15 секунд. То есть вам вообще почти не придется ждать, пока именно вашу капчу разгадают.
Проект пригоден для распознавания прямо в браузере. Обоюдно полезный вариант, который может помочь заработать новичкам, и в то же время облегчить работу профессионалам.
Какой из сервисов выбрать – решайте сами. Каждый обладает своими достоинствами и недостатками. Можно сказать одно: каждый проект работает уже достаточно длительное время. Вы можете не беспокоиться, что вас обманут, украдут ваши деньги или зашлют какие-нибудь вирусы на ПК. Такого точно не будет, однако, этого не скажешь про других.

Будьте внимательны при выборе сервиса антикапчи. В Рунете полным-полно фейков, которые занимаются мошенничеством. Если вы вдруг решили попробовать более дешевый неизвестный проект, то лучше бы вам перед использованием проверить отзывы о нем. Вполне возможно, что это фишинговый ресурс, который занимается сбором денег с доверчивых пользователей.
Инструкция по работе с сервисами
После того, как вы выберете онлайн-сервис антикапчи, вам нужно будет как-то его использовать. Обычно в таких сервисах есть специальные ключи – их вы получаете в своем аккаунте, после чего вводите в специальное поле приложения. В рамках сегодняшнего материала я рассмотрю РуКапчу.
Переходим в раздел “API вебмастеру”, где видим примерно такую картину.

Здесь есть поле “captcha KEY” – оно-то нам и нужно. Копируем этот ключик и идем в настройки антикапчи нашей программы.

Ставим галочку “Использовать сервис антикапчи”, выбираем сервис из выпадающего списка и вставляем ключ. Готово! Теперь наше приложение будет автоматически “разгадывать” капчу при помощи соответствующего сервиса. Больше никаких действий от вас не требуется. Только своевременно пополняйте счет на сайте.
Настройки во всех этих программах почти не отличаются. И в Кей Коллекторе, и в СловоЁбе, и в любом другом приложении все будет выглядеть примерно так, как я описал.
Заключение
Теперь вы знаете, как обойти ввод символов и различные проверки “Вы не робот?” с помощью онлайн-сервисов. Удобная практика и простая реализация. Вы можете навсегда убрать капчу из своей жизни, лишь изредка пополняя баланс. Как правило, на такие проекты уходит очень мало денег, но зато сколько пользы.
В том же Кей Коллекторе эта капча может очень часто вылетать, мешая вам выполнять свою работу. А так, подключили программу к сервису, запустили сбор семантического ядра и можно заняться своими делами. То же касается и других утилит, которые требуют постоянного ввода символов.