Что такое мультикаст в роутере. Требования к ресурсам системы. Multicast и Unicast: ключевые различия
Первым делом озвучим несколько понятий, чтоб исключить дальнейшие недопонимания. Существует три вида трафика:
- unicast — одноадресный, один источник потока один получатель
- broadcast — широковещательный, один источник, получатели все клиенты в сети
- multicast — многоадресный, один отправитель, получатели некоторая группа клиентов
Какой вид трафика использовать для IPTV?
Очевидно, что для вещания каналов наибольшее предпочтение отдается multicast.
Любой TV-канал, который мы хотим вещать в сеть, характеризуется адресом группы, который выбирается из диапазона, зарезервированного для этих целей: 224.0.0.0 - 239.255.255.255
.
Создание групповой трансляции
Ответы также отправляются на адрес 1 и прослушиваются на других станциях. Это позволяет избежать дублирования передачи запросов в ту же группу. Это то, к чему используются так называемые протоколы роуминга. Их шлемы ищут минимальную древовидную связь, покрывающую путь от источника передатчика группы до моментальных регистраторов. Очевидно, что, помимо классического трюизма прямого вещания, процесс очень динамичен. Путь от данного источника к заданной цели является истинным, если не происходит изменения топологии сети, пунктирные линии.
Для работы IPTV необходим роутер, поддерживающий multicast (далее MR). Он будет отслеживать членство того или иного клиента в определенной группе, т.е. постоянно следить какому клиенту какой отправлять TV-канал.
Для того чтобы клиент смог зарегистрироваться в одной из этих групп и смотреть TV-канал используется протокол IGMP (Internet Group Management Protocol).
Мгновенная доступность и пропускная способность приложений
С другой стороны, получатели данной групповой трансляции могут быть созданы и уничтожены постоянно, и этот процесс дополнительных изменений в протоколах объединения должен быть надлежащим образом отражен. Оптимизация протоколов вещания по-прежнему является предметом интенсивных исследований и разработок. В предыдущей интерпретации, где мы не проводили различие между грубой и контрабандой, поощряли групповое вещание, могло сложиться впечатление, что поддержка группового вещания является органической частью контрабандистов, и это не следует помнить.
Немного о том, как работает IGMP.
Есть сервер, который включен в роутер MR. Этот сервер вещает несколько TV-мультиков, например:Клиент включает канал News, тем самым, сам не подозревая, он отправляет запрос на MR для подключения к группе 224.12.0.1. С точки зрения протокола IGMP это запрос “JOIN 224.12.0.1 ”.
Если пользователь переключается на другой канал, то он сначала отправляет уведомление MR, что он отключает канал News или покидает эту группу. Для IGMP это “LEAVE 224.12.0.1 ”. А затем повторяет аналогичный запрос JOIN для нужного канала.
Реальность немного сложная. Несмотря на то, что в течение длительного времени для группового вещания были задуманы разные стандарты, они давно знают о разработке приложений с пропускной способностью в заявлениях контрабандистов о том, что групповое вещание не предполагается поддерживать, поскольку они не являются приложениями. Путь от этой ловушки привел к внедрению специальных групповых роботов на рабочие станции, подключенные к локальным сетям, экспериментируя с групповым радиовещанием. Их так называемые «туннели» имели свои взаимосвязанные соединения, когда пакеты пакетных пакетов были упакованы в прямые передачи между мьютерами.
MR иногда спрашивает всех: “а какой группе кто подключен?”, чтобы отключать тех клиентов, с которыми оборвалась связь и они не успели отправить уведомление LEAVE . Для этого MR использует запрос QUERY .
Ответ абонента на этот запрос это MEMBERSHIP REPORT , который содержит список всех групп, в которых состоит клиент.
Настройка multicast routing.
Предположим, что клиенты одной группы смотрят один и тот же мультик, но находятся они в разных сегментах сети (network A и network B). Для того, чтобы они получили свой мультик и придуман multicast routing.
В это время ситуация знакома, практически каждый промышленно производимый мошенник поддерживает групповое вещание и некоторый протокол роуминга. Тем не менее, никаких неприятных сюрпризов не исключено, особенно при смене версий программируемого оборудования для более гладких. Кроме того, сотрудник различных производителей имеет много общего с приключениями, а не рутинными проблемами.
Добавление к части столичной области в Брно обусловлено импульсом используемых сглаживаний и является предметом дальнейших разработок. Как уже упоминалось во введении, существующие приложения были в области мультимедиа. Фактически, односторонняя передача изображения и звука все переносит определенную степень ненадежности передачи, не ставя под угрозу все приложение. Движение изображения менее когерентное, звук имеет падение, но оба могут быть допущены после определенного предела.
Пример настройки роутеров MR1 и MR2.
| Network A | 10.1.0.0/24 |
| Network B | 10.2.0.0/24 |
| Network C | 10.3.0.0/24 |
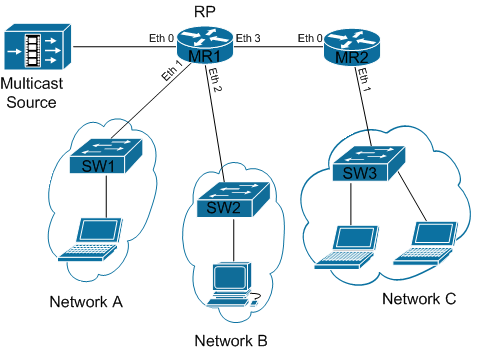
| MR1 | MR2 |
| MR1#sh run Ip multicast-routing Таким образом, стоит упомянуть, что мы не встречали информационные бюллетени на страницах рассылок в последний раз. Стоит отметить, что этот процесс известен как инкапсуляция. Затем пакет отправляется через сеть получателю. Рассмотрим первый из двух случаев: адрес получателя находится в той же подсети, что и адрес отправителя. Такая ситуация возникает, когда два компьютера или другие сетевые устройства подключаются напрямую через сетевой кабель или через коммутатор. Устройства в одной подсети знают, как отправить пакет друг другу. Им нужна только информация о физическом адресе сетевой карты отправителя. Второй, немного более сложный случай - когда адрес получателя находится в другой подсети, чем адрес отправителя. Здесь, к сожалению, невозможно напрямую отправить пакет отправителю и первую скрипку в сетевых устройствах, которые называются маршрутизаторами. Маршрутизатор собирается пересылать пакеты между разными подсетями. В большинстве случаев путь между отправителем и получателем состоит из нескольких или нескольких десятков маршрутизаторов, которые связаны друг с другом разными маршрутами, поэтому существует множество возможных путей выбора. |
MR2#sh run Ip multicast-routing |
Команда "ip multicast-routing " включает соответствующий routing, если же он выключен, то роутер не пересылает multicast пакеты, т.е. они не дойдут до недоумевающего зрителя мультиков.
Остановимся чуть поподробнее на команде "ip pim sparse-mode ".
Задача маршрутизаторов - выбрать наилучший возможный маршрут для доставки пакета в пункт назначения. Этот выбор выполняется в зависимости от заданных критериев, например, максимальной пропускной способности, наименьших задержек, наименьших устройств на этом пути и т.д. в большинстве операционных систем и сетевых устройств этот адрес называется адресом шлюза по умолчанию. Он фактически определяет устройство, через которое пакет будет отправлен, если отправитель не знает, что с ним делать.
Поэтому, если отправитель уже знает, что получатель вышел из своей локальной сети, он не думает, как доставить пакет к нему, но отправляет его только через шлюз по умолчанию, если он имеет один набор в своей конфигурации. Маршрутизаторы, которые находятся на пути от источника к месту назначения, выбирают лучший маршрут на основе их таблиц маршрутизации. Поскольку сетевые условия часто меняются, маршрутизаторы должны принимать решения о лучших маршрутах на постоянной основе.
Про режимы протокола PIM и сам протокол.
PIM (Protocol Independent Multicast) — протокол маршрутизации multicast рассылки. Он заполняет свою таблицу multicast маршрутизации на основе обычной таблицы маршрутизации. Эти таблицы можно просмотреть с помощью команд “sh ip mroute ” и “sh ip route ” соответственно. Целью протокола PIM является построение дерева маршрутов для рассылки multicast сообщений.
У протокола PIM существует два основных режима: разряженный (sparse mode
) и плотный (dense mode
). Таблица multicast маршрутизации для них выглядит немного по-разному. Иногда эти режимы рассматривают как отдельные протоколы — PIM-SM и PIM-DM.
Высокая производительность и высокий уровень контроля
Благодаря сложным инструментам вы получаете возможность контролировать уровень сигнала, изменять настройки родительского контроля и другие функции полностью интуитивным способом.
Высокая скорость и дальность передачи
Используйте, транслируйте, синхронизируйте и делите все свои файлы на ходу, как из государственных, так и частных облачных сервисов хранения.Двухчастотная поддержка обеспечивает плавное подключение
Он обеспечивает оптимизированный сигнал в каждом направлении и, таким образом, увеличивает пропускную способность сети.
Простая настройка с помощью планшета, смартфона или компьютера
Пользователю будет предложено ввести идентификатор и пароль, предоставленные поставщиком услуг Интернета.В нашей конфигурации на интерфейсах мы указали режим "ip pim sparse-mode ".
(config-if)# ip pim?
Dense-mode Enable PIM dense-mode operation
sparse-dense-mode Enable PIM sparse-dense-mode operation
sparse-mode Enable PIM sparse-mode operation
………
В чем же разница?
PIM-DM использует механизм лавинной рассылки и отсечения (flood and prune). Другими словами. Роутер MR отправляет всем все multicast потоки, которые на нем зарегистрированы. Если клиенту не нужен какой-то из этих каналов, то он от него отказывается. Если все клиенты, висящие на роутере, отказались от канала, то роутер пересылает “спасибо, не надо” вышестоящему роутеру.PIM-SM изначально не рассылает зарегистрированные на нем TV-каналы. Рассылка начнется только тогда, когда от клиента придет на нее запрос.
Мощные функции, простое управление
Конфигурация сети теперь проще, чем когда-либо. Решение позволяет управлять всеми клиентскими устройствами и настройками с помощью единого графического интерфейса. Вы много играете или смотрите фильмы в Интернете? Благодаря монитору сетевого трафика, пользователь может проверить использование сетевых ресурсов с помощью четкого интерфейса.
Отдельные, безопасные гостевые сети
Благодаря этому обеспечивается чрезвычайно плавное соединение. Параметры родительского контроля позволяют настроить время, которое дети могут потратить на Интернет. Мы живем во времена публичной информации, источником которой до сих пор являлись средства массовой информации, пассивно передающие нам контент. Мы могли наблюдать за ними, слушать их или читать. В течение нескольких лет мы являемся не только бенефициарами информации, но и активным образом можем реагировать на нее и даже создавать ее. Первоначально этот период был связан с высокими требованиями к ИТ-навыкам.
Т.е. в PIM-DM MR отправляет всем, а потом убирает ненужное, а в PIM-SM MR начинает вещание только по запросу.
Если члены группы разбросаны по множеству сегментов сети, что характерно для IPTV, PIM-DM будет использовать большую часть полосы пропускания. А это может привести к снижению производительности. В этом случае лучше использовать PIM-SM.
Производители аппаратного и программного обеспечения, видящие повсеместный спрос на возникающую тенденцию, начали создавать устройства и программы, которые проще и ориентированы на пользователей. Такая эволюция привела к посещению наших домов в первую очередь компьютерами, а затем к первым формам Интернета. Затем из года в год вы могли наблюдать увеличение требований к скорости ваших соединений, наконец, предлагая домашним пользователям скорость, которая всего несколько лет назад оставалась доступной для хостинговых компаний.
Является ли это достаточной причиной для покупки описанной модели? Давайте посмотрим, что еще мы можем получить, потратив около 700 злотых. Проблема эстетики не должна определяться выбором той или иной модели маршрутизатора. Половина проблем, если мы можем настроить маршрутизатор и спрятать его в темном шкафу или в другом не очень заметном месте. Некоторые из нас не могут этого сделать или просто не хотят. Тогда внешний вид не может опускаться в фоновом режиме, и он начинает представлять собой довольно важный актив или дефект, который в конечном итоге может решить купить ту или иную единицу.
Между PIM-DM и PIM-SM существуют еще отличия.
PIM-DM строит дерево отдельно для каждого источника определенной multicast группы, т.е. multicast маршрут будет характеризоваться адресом источника и адресом группы. В multicast таблице маршрутизации будут записи вида (S,G), где S — source, G — group.

Тогда наш партнер вышвырнет такое устройство из дома вместе с нами. Как вы можете видеть на картинке выше, формат устройства и текстура передней панели связаны с женским кошельком, так называемым. «Сцепление». Таким образом, мужской пол будет удовлетворен функциями устройства, в то время как женский пол будет хорошо выглядеть. Обращаясь к существу, следует отметить, что мы представляем устройство в пакете, содержащем.
После распаковки устройства вы сразу увидите, что он был разработан для работы в одной позиции. Вы не можете опустить его, поместить его вертикально боком или повесить на стену. На передней панели устройства имеются диоды, указывающие. Стоит отметить, что производитель разместил табличку с описанием настроек по умолчанию и графической информацией, включая чертеж доступных кнопок, а также описание их функций. Эта информация особенно ценится, когда нам нужно восстановить заводские настройки и перенастроить ее с самого начала.
У PIM-SM есть некоторая особенность. Этому режиму необходима точка рандеву (RP — rendezvous point ) на которой будут регистрироваться источники multicast потоков и создавать маршрут от источника S (себя) до группы G: (S,G).
Таким образом, трафик идет с источника до RP по маршруту (S,G), а далее до клиентов уже по общему для источников определенной группы дереву, которое характеризуется маршрутом (*,G) — "*" символизирует «любой источник». Т.е. источники зарегистрировались на RP, и далее клиенты уже получают поток с RP и для них не имеет значения, кто был первоначальным источником. Корнем этого общего дерева будет RP.

Точкой рандеву является один из multicast роутеров, но все остальные роутеры должны знать “кто здесь точка RP”, и иметь возможность до нее достучаться.
Пример статического определения RP (MR1). Объявим всем multicast роутерам, что точкой рандеву является 10.0.0.1 (MR1):
Все остальные роутеры должны знать маршрут до RP:
ip route 10.0.0.0 255.255.255.0 10.10.10.1
Существуют так же и другие способы определения RP, это auto-RP и bootstarp router, но это уже тема для отдельной статьи (если кому-нибудь будет интересно - пожалуйста )?
Посмотрим, что будет происходить после настройки роутеров.
Мы по-прежнему рассматриваем схему с роутерами MR1 (RP) и MR2. Как только включаем линк между роутерами MR1 и MR2, то должны увидеть в логах сообщенияДля MR1:
%PIM-5-NBRCHG: neighbor 10.10.10.2 UP on interface Ethernet3
Для MR2:
%PIM-5-NBRCHG: neighbor 10.10.10.1 UP on interface Ethernet0
Это говорит о том, что роутеры установили отношение соседства по протоколу PIM друг с другом. Проверить это также можно с помощью команды:
MR1#sh ip pim neighbor
PIM Neighbor Table
Mode: B — Bidir Capable, DR — Designated Router, N — Default DR Priority, S — State Refresh Capable
| Neighbor Address | Interface | Uptime/Expires | Ver | DR Prio/Mode |
| 10.10.10.2 | Ethernet3 | 00:03:05/00:01:37 | v2 | 1 / DR S |
Не забываем про TTL.
В качестве тестового сервера мне было удобно использовать плеер VLC. Однако, как позже обнаружилось, даже если выставить через GUI достаточный TTL, он все равно (надеюсь только в использованной мной версией) упорно отправлял multicast пакеты с TTL=1. Запускать упрямого пришлось с опцией «vlc.exe -ttl 3» т.к. у нас на пути будет два роутера, каждый из которых уменьшает TTL пакета на единицу.Как же все таки обнаружить проблему с TTL? Один из способов. Пусть сервер вещает канал 224.12.0.3 с TTL=2, тогда на роутере MR1 пакеты проходят нормально, а за роутером MR2 клиенты уже не смогут смотреть свой мультик.
Обнаруживается это с помощью команды «sh ip traffic» на MR2. Смотрим на поле “bad hop count” - это число пакетов, которые “умерли”, как им и отмеряно, по TTL=0.
MR2#sh ip traffic
IP statistics:
Rcvd: 36788 total, 433 local destination
0 format errors, 0 checksum errors, 2363 bad hop count
……………………………………
Если этот счетчик быстро увеличивается, значит — проблема в TTL.
Show ip mroute
После включения вещания трех каналов на сервере в таблице multicast маршрутизации наблюдаем следующее:MR1# sh ip mroute
(*, 224.12.0.1), 00:03:51/stopped, RP 10.0.0.1, flags: SP
(10.0.0.2, 224.12.0.1), 00:03:52/00:02:50, flags: PT
Outgoing interface list: Null
(*, 224.12.0.2), 00:00:45/stopped, RP 10.0.0.1, flags: SP
Incoming interface: Null, RPF nbr 0.0.0.0
Outgoing interface list: Null
(10.0.0.2, 224.12.0.2), 00:00:45/00:02:50, flags: PT
Incoming interface: Ethernet0, RPF nbr 0.0.0.0
Outgoing interface list: Null
(*, 224.12.0.3), 00:00:09/stopped, RP 10.0.0.1, flags: SP
Incoming interface: Null, RPF nbr 0.0.0.0
Outgoing interface list: Null
(10.0.0.2, 224.12.0.3), 00:00:09/00:02:59, flags: PT
Incoming interface: Ethernet0, RPF nbr 0.0.0.0
Outgoing interface list: Null
Видим, что появились маршруты вида (S,G), например (10.0.0.2, 224.12.0.3), т.е. зарегистрировался источник 10.0.0.2, который вещает для группы 224.12.0.3. А так же маршруты с RP до клиента: (*,G), например (*, 224.12.0.3) - которые они будут использовать, так называемое общее для всех дерево.
Как только на интерфейс MR1 (RP) приходит запрос на получение канала 1, в multicast таблице маршрутизации происходят следующие изменения:
MR1#sh ip mroute
…………………
(*, 224.12.0.1), 00:33:16/00:02:54, RP 10.0.0.1, flags: S
Incoming interface: Null, RPF nbr 0.0.0.0
Outgoing interface list:
(10.0.0.2, 224.12.0.1), 00:33:17/00:03:25, flags: T
Incoming interface: Ethernet0, RPF nbr 0.0.0.0
Outgoing interface list:
Ethernet3, Forward/Sparse, 00:02:37/00:02:53
Стало видно, что приходят запросы на эту группу с порта Ethernet3.
RPF проверка
Возможна ситуация, когда роутер получает multicast поток на двух интерфейсах. Кого из этих двух интерфейсов роутер будет считать источником?Для этого он выполняет проверку RPF (Reverse Path Forwarding) — проверяет по обычной unicast таблице маршрутизации маршрут до источника и выбирает тот интерфейс, через который идет маршрут до этого источника. Эта проверка необходима для того чтобы избежать образования петель.

Отследить, как источник проходит проверку RPF можно с помощью команды:
MR2#sh ip rpf ?
Hostname or A.B.C.D IP name or address of multicast source
MR2#sh ip rpf 10.0.0.2
RPF information for? (10.0.0.2)
RPF interface: Ethernet0
RPF neighbor:? (10.10.10.1)
RPF route/mask: 10.0.0.0/24
RPF type: unicast (static)
RPF recursion count: 0
Doing distance-preferred lookups across tables
Наш умозрительный провайдер linkmeup взрослеет и обрастает по-тихоньку всеми услугами обычных операторов связи. Теперь мы доросли до IPTV.
Отсюда вытекает необходимость настройки мультикастовой маршрутизации и в первую очередь понимание того, что вообще такое мультикаст.
Это первое отклонение от привычных нам принципов работы IP-сетей. Всё-таки парадигма многоадресной рассылки в корне отличается от тёплого лампового юникаста.
Можно даже сказать, это в некоторой степени бросает вызов гибкости вашего разума в понимании новых подходов.
В этой статье сосредоточимся на следующем:
Традиционный видеоурок:
На заре моего становления, как инженера, тема мультикаста меня неимоверно пугала, и я связываю это с психотравмой моего первого опыта с ним.
«Так, Марат, срочно, до полудня нужно пробросить видеопоток до нашего нового здания в центре города - провайдер отдаст его нам тут на втором этаже » - услышал я одним чудесным утром. Всё, что я тогда знал о мультикасте, так это то, что отправитель один, получателей много, ну и, кажется, протокол IGMP там как-то задействован.В итоге до полудня мы пытались всё это дело запустить - я пробросил самый обычный VLAN от точки входа до точки выхода. Но сигнал был нестабильным - картинка замерзала, разваливалась, прерывалась. Я в панике пытался разобраться, что вообще можно сделать с IGMP, тыркался, тыркался, включал мультикаст роутинг, IGMP Snooping, проверял по тысяче раз задержки и потери - ничего не помогало. А потом вдруг всё заработало. Само собой, стабильно, безотказно.
Это послужило мне прививкой против мультикаста, и долгое время я не проявлял к нему никакого интереса.
Уже гораздо позже я пришёл в к следующему правилу:
И теперь с высоты оттраблшученных кейсов я понимаю, что там не могло быть никаких проблем с настройкой сетевой части - глючило конечное оборудование.

Сохраняйте спокойствие и доверьтесь мне. После этой статьи такие вещи вас пугать не будут.
Общее понимание Multicast
Как известно, существуют следующие типы трафика:Unicast - одноадресная рассылка - один отправитель, один получатель. (Пример: запрос HTTP-странички у WEB-сервера ).
Broadcast - широковещательная рассылка - один отправитель, получатели - все устройства в широковещательном сегменте. (Пример: ARP-запрос ).
- многоадресная рассылка - один отправитель, много получателей. (Пример: IPTV ).
Anycast - одноадресная рассылка ближайшему узлу - один отправитель, вообще получателей много, но фактически данные отправляются только одному. (Пример: Anycast DNS ).
Раз уж мы решили поговорить о мультикасте, то, пожалуй, начнём этот параграф с вопроса, где и как он используется.
Первое, что приходит на ум, - это телевидение (IPTV) - один сервер-источник отправляет трафик, который хочет получать сразу много клиентов. Это и определяет сам термин - - многоадресное вещание. То есть, если уже известный вам Broadcast означает вещание всем, мультикаст означает вещание определённой группе.
Второе применение - это, например, репликация операционной системы на множество компьютеров разом. Это подразумевает загрузку больших объёмов данных с одного сервера.
Возможные сценарии: аудио и видеоконференции (один говорит - все слушают), электронная коммерция, аукционы, биржи. Но это в теории, а на практике редко тут всё-таки используется мультикаст.
Ещё одно применение - это служебные сообщения протоколов. Например, OSPF в своём широковещательном домене рассылает свои сообщения на адреса 224.0.0.5 и 224.0.0.6. И обрабатывать их будут только те узлы, на которых запущен OSPF.
Сформулируем два основных принципа мультикастовой рассылки:
- Отправитель посылает только одну копию трафика, независимо от количества получателей.
- Трафик получают только те, кто действительно заинтересован в нём.
Пример I
Начнём с самого простого случая:
На сервере-источнике настроено вещание в группу 224.2.2.4 - это означает, что сервер отправляет трафик на IP-адрес 224.2.2.4. На клиенте видеоплеер настроен принимать поток группы 224.2.2.4.
При этом, заметьте, клиент и сервер не обязательно должны иметь адреса из одной подсети и пинговать друг друга - достаточно, чтобы они были в одном широковещательном домене.
Мультикастовый поток просто льётся с сервера, а клиент его просто принимает. Вы можете попробовать это прямо у себя на рабочем месте, соединив патчкордом два компьютера и запустив, например, VLC.
Надо заметить, что в мультикасте нет никакой сигнализации от источника, мол, «Здрасьте, я Источник, не надо немного мультикаста?»
.
Сервер-источник просто начинает вещать в свой интерфейс мультикастовые пакеты. В нашем примере они напрямую попадают клиенту и тот, собственно, сразу же их и принимает.
Если на этом линке отловить пакеты, то вы увидите, что мультикастовый трафик - это ни что иное, как море UDP-пакетов.
Мультикаст не привязан к какому-то конкретному протоколу. По сути, всё, что его определяет - адреса. Однако, если говорить о его применении, то в абсолютном большинстве случаев используется именно UDP. Это легко объясняется тем, что обычно с помощью многоадресной рассылки передаются данные, которые нужны здесь и сейчас. Например, видео. Если кусочек кадра потеряется, и отправитель будет пытаться его послать повторно, как это происходит в TCP, то, скорее всего, этот кусочек опоздает, и где его тогда показывать? Поезд ушёл. Ровно то же самое со звуком.
Соответственно не нужно и устанавливать соединение, поэтому TCP здесь ни к чему.
Чем же так разительно отличается мультикаст от юникаста? Думаю, у вас есть уже предположение. И вы, наверняка, правы.
В обычной ситуации у нас 1 получатель и 1 отправитель - у каждого из них один уникальный IP-адрес. Отправитель точно знает, куда надо слать пакет и ставит этот адрес в заголовок IP. Каждый промежуточный узел благодаря своей таблице маршрутизации точно знает, куда переслать пакет. Юникастовый трафик между двумя узлами беспрепятственно проходит сквозь сеть. Но проблема в том, что в обычном пакете указывается только один IP-адрес получателя.
Что делать, если у одного и того же трафика несколько получателей? В принципе можно расширить одноадресный подход и на такую ситуацию - отправлять каждому клиенту свой экземпляр пакета. Клиенты не заметят разницы - хоть он один, хоть их тысяча, но разница будет отчётливо различима на ваших каналах передачи данных.
Предположим у нас идёт передача одного SD-канала с мультикаст-сервера. Пусть, он использует 2 Мб/с. Всего таких каналов 30, а смотрит каждый канал по 20 человек одновременно. Итого получается 2 Мб/с * 30 каналов * 20 человек = 1200 Мб/с или 1,2 Гб/с только на телевидение в случае одноадресной рассылки. А есть ведь ещё HD каналы, где можно смело умножать эту цифру на 2. И где тут место для торрентов?
Вот почему в IPv4 был заложен блок адресов класса D: 224.0.0.0/4
(224.0.0.0-239.255.255.255). Адреса этого диапазона определяют мультикастовую группу. Один адрес - это одна группа, обычно она обозначается буквой «G
».
То есть, говоря, что клиент подключен к группе 224.2.2.4, мы имеем ввиду, что он получает мультикастовый трафик с адресом назначения 224.2.2.4.
Пример II
Добавим в схему коммутатор и ещё несколько клиентов:
Мультикастовый сервер по-прежнему вещает для группы 224.2.2.4. На коммутаторе все 4 порта должны быть в одном VLAN. Трафик приходит на коммутатор и по умолчанию рассылается во все порты одного VLAN"а. Значит все клиенты получают этот трафик. На них на всех в видеопроигрывателе так же указан групповой адрес 224.2.2.4.
Собственно, все эти устройства становятся членами данной мультикастовой группы. Членство в ней динамическое: кто угодно, в любой момент может войти и выйти из неё.
В данной ситуаци трафик будут получать даже те, кто этого в общем-то и не хотел, то есть на нём не запущен ни плеер, ни что бы то ни было другое. Но только, если он в том же VLAN"е. мы разберёмся, как с этим бороться.Обратите внимание, что в данном случае от сервера-источника приходит только одна копия трафика на коммутатор, а не по отдельной копии на каждого клиента. И в нашем примере с SD каналами загрузка порта между источником и коммутатором будет не 1,2 Гб/с, а всего 60 Мб/с (2Мб/с * 30 каналов).
Собственно говоря, весь этот огромный диапазон (224.0.0.0-239.255.255.255) можно использовать.
Ну, почти весь - первые адреса (диапазон 224.0.0.0/23) всё-таки зарезервированы под известные протоколы.
Список зарезервированных IP-адресов
| Адрес | Значение |
|---|---|
| 224.0.0.0 | Не используется |
| 224.0.0.1 | Все узлы данного сегмента |
| 224.0.0.2 | Все мультикастовые узлы данного сегмента |
| 224.0.0.4 | Данный адрес выделялся для покойного протокола DVMRP |
| 224.0.0.5 | Все OSPF-маршрутизаторы сегмента |
| 224.0.0.6 | Все DR маршрутизаторы сегмента |
| 224.0.0.9 | Все RIPv2-маршрутизаторы сегмента |
| 224.0.0.10 | Все EIGRP-маршрутизаторы сегмента |
| 224.0.0.13 | Все PIM-маршрутизаторы сегмента |
| 224.0.0.18 | Все VRRP-маршрутизаторы сегмента |
| 224.0.0.19-21 | Все IS-IS-маршрутизаторы сегмента |
| 224.0.0.22 | Все IGMP-маршрутизаторы сегмента (v2 и v3) |
| 224.0.0.102 | Все HSRPv2/GLBP-маршрутизаторы сегмента |
| 224.0.0.107 | PTPv2 - Precision Time Protocol |
| 224.0.0.251 | mDNS |
| 224.0.0.252 | LLMNR |
| 224.0.0.253 | Teredo |
| 224.0.1.1 | NTP |
| 224.0.1.39 | Cisco Auto-RP-Announce |
| 224.0.1.40 | Cisco Auto-RP-Discovery |
| 224.0.1.41 | H.323 Gatekeeper |
| 224.0.1.129-132 | PTPv1/PTPv2 |
| 239.255.255.250 | SSDP |
Диапазон 224.0.0.0/24 зарезервирован под коммуникации. Мультикастовые пакеты с такими адресами назначения не могут выходить за пределы одного широковещательного сегмента.
Диапазон 224.0.1.0/24 зарезервирован под протоколы, которым необходимо передавать мультикаст по всей сети, то есть проходить через маршрутизаторы.
Вот, собственно, самые базисные вещи касательно мультикаста.
Мы рассмотрели простую ситуацию, когда источник и получатель находятся в одном сегменте сети. Трафик, полученный коммутатором, просто рассылается им во все порты - никакой магии.
Но пока совсем непонятно, как трафик от сервера достигает клиентов, когда между ними огромная провайдерская сеть линкмиап? Да и откуда, собственно, будет известно, кто клиент? Мы же не можем вручную прописать маршруты, просто потому что не знаем, где могут оказаться клиенты. Не ответят на этот вопрос и обычные протоколы маршрутизации. Так мы приходим к пониманию, что доставка мультикаст - это нечто совершенно новое для нас.
Вообще, чтобы доставить мультикаст от источника до получателя на данный момент существует много протоколов - IGMP/MLD, PIM, MSDP, MBGP, MOSPF, DVMRP.
Мы остановимся на двух из них, которые используются в настоящее время: PIM и IGMP.
С помощью IGMP конечные получатели-клиенты сообщают ближайшим маршрутизаторам о том, что хотят получать трафик. А PIM строит путь движения мультикастового трафика от источника до получателей через маршрутизаторы.

IGMP
Снова вернёмся к дампу. Видите вот этот верхний пакет, после которого полился мультикастовый поток?Это сообщение протокола IGMP, которое отправил клиент, когда мы на нём нажали Play. Именно так он сообщает о том, что хочет получать трафик для группы 224.2.2.4.
IGMP - Internet Group Management Protocol
- это сетевой протокол взаимодействия клиентов мультикастового трафика и ближайшего к ним маршрутизатора.
В IPv6 используется (Multicast Listener Discovery) вместо IGMP. Принцип работы у них абсолютно одинаковый, поэтому далее везде вы смело можете менять IGMP на MLD, а IP на IPv6.
Как же именно работает IGMP?
Пожалуй, начать нужно с того, что версий у протокола сейчас три: IGMPv1, IGMPv2, IGMPv3. Наиболее используемая - вторая, первая уже практически забыта, поэтому про неё говорить не будем, третья очень похожа на вторую.
Акцентируемся пока на второй, как на самой показательной, и рассмотрим все события от подключения клиента к группе до его выхода из неё.
Клиент будет также запрашивать группу 224.2.2.4 через проигрыватель VLC.
Роль IGMP очень проста: если клиентов нет - передавать мультикастовый трафик в сегмент не надо. Если появился клиент, он уведомляет маршрутизаторы с помощью IGMP о том, что хочет получать трафик.
Для того, чтобы понять, как всё происходит, возьмём такую сеть:

Предположим, что маршрутизатор уже настроен на получение и обработку мультикастового трафика.
1. Как только мы запустили приложение на клиенте и задали группу 224.2.2.4, в сеть будет отправлен пакет - узел «рапортует» о том, что хочет получать трафик этой группы.

В IGMPv2 Report отправляется на адрес желаемой группы, и параллельно он же указывается в самом пакете. Данные сообщения должны жить только в пределах своего сегмента и не пересылаться никуда маршрутизаторами, поэтому и TTL у них 1.
Часто в литературе вы можете встретить упоминание о IGMP Join . Не пугайтесь - это альтернативное название для IGMP Membership Report.
2. Маршрутизатор получает IGMP-Report и, понимая, что за данным интерфейсом теперь есть клиенты, заносит информацию в свои таблицы
Это вывод информации по IGMP. Первая группа запрошена клиентом. Третья и четвёртая - это служебные группы протокола , встроенного в Windows. Вторая - специальная группа, которая всегда присутствует на маршрутизаторах Cisco - она используется для протокола , который по умолчанию активирован на маршрутизаторах.
Интерфейс FE0/0 становится нисходящим для трафика группы 224.2.2.4 - в него нужно будет отправлять полученный трафик.
Наряду с обычной юникастовой таблицей маршрутизации существует ещё и мультикастовая:
![]()
О наличии клиентов говорит первая запись (*, 224.2.2.4)
. А запись (172.16.0.5, 224.2.2.4)
означает, что маршрутизатор знает об источнике мультикастового потока для этой группы.
Из вывода видно, что трафик для группы 224.2.2.4 приходит через FE0/1, а передавать его надо на порт FE0/0.
Интерфейсы, в которые нужно передавать трафик, входят в список нисходящих интерфейсов - OIL - Outbound Interface List
.
Более подробно вывод команды мы разберём позже.
Выше на дампе вы видите, что как только клиент отправил IGMP-Report, сразу после него полетели UDP - это видеопоток.
3.
Клиент начал получать трафик. Теперь маршрутизатор должен иногда проверять, что получатели до сих пор у него есть, чтобы зазря не вещать, если вдруг клиентов не осталось. Для этого он периодически отправляет во все свои нисходящие интерфейсы запрос IGMP Query
.
*Дамп отфильтрован по IGMP*
.
По умолчанию это происходит каждые 60 секунд. TTL таких пакетов тоже равен 1. Они отправляются на адрес 224.0.0.1 - все узлы в этом сегменте - без указания конкретной группы. Такие сообщений Query называются General Query - общие. Таким образом маршрутизатор спрашивает: «Ребят, а кто и что ещё хочет получать?».
Получив IGMP General Query, любой хост, который слушает любую группу, должен отправить IGMP Report, как он это делал при подключении. В Report, естественно, должен быть указан адрес интересующей его группы.
*Дамп отфильтрован по IGMP*
.
Если в ответ на Query на маршрутизатор пришёл хотя бы один Report для группы, значит есть ещё клиенты, он продолжает вещать в тот интерфейс, откуда пришёл этот Report, трафик этой самой группы.
Если на 3 подряд Query не было с интерфейса ответа для какой-то группы, маршрутизатор удаляет этот интерфейс из своей таблицы мультикастовой маршрутизации для данной группы - перестаёт туда посылать трафик.
По своей инициативе клиент обычно посылает Report только при подключении, потом - просто отвечает на Query от маршрутизатора.
Интересная деталь в поведении клиента: получив Query, он не торопится сразу же ответить Report"ом. Узел берёт тайм-аут длиной от 0 до , который указан в пришедшем Query:
При отладке или в дампе, кстати, можно видеть, что между получением различных Report может пройти несколько секунд.
Сделано это для того, чтобы сотни клиентов все скопом не наводнили сеть своими пакетам Report, получив General Query. Более того, только один клиент обычно отправляет Report.
Дело в том, что Report отсылается на адрес группы, а следовательно доходит и до всех клиентов. Получив Report от другого клиента для этой же группы, узел не будет отправлять свой. Логика простая: маршрутизатор и так уже получил этот самый Report и знает, что клиенты есть, больше ему не надо.
Этот механизм называется Report Suppression .

4. Так продолжается веками, пока клиент не захочет выйти из группы (например, выключит плеер/телевизор). В этом случае он отправляет на адрес группы.

Маршрутизатор получает его и по идее должен отключить. Но он ведь не может отключить одного конкретного клиента - маршрутизатор их не различает - у него просто есть нисходящий интерфейс. А за интерфейсом может быть несколько клиентов. То есть, если маршрутизатор удалит этот интерфейс из своего списка OIL (Outgoing Interface List) для этой группы, видео выключится у всех.
Но и не удалять его совсем тоже нельзя - вдруг это был последний клиент - зачем тогда впустую вещать?
Если вы посмотрите в дамп, то увидите, что после получения Leave маршрутизатор ещё некоторое время продолжает слать поток. Дело в том, что маршрутизатор в ответ на Leave высылает IGMP Query на адрес группы, для которой этот Leave пришёл в тот интерфейс, откуда он пришёл. Такой пакет называется Group Specific Query . На него отвечают только те клиенты, которые подключены к данной конкретной группе.

Если маршрутизатор получил ответный Report для группы, он продолжает вещать в интерфейс, если не получил - удаляет по истечении таймера.
Всего после получения Leave отправляется два Group Specific Query - один обязательный, второй контрольный.
*Дамп отфильтрован по IGMP*
.
Querier
Рассмотрим чуть более сложный случай:
В клиентский сегмент подключено два (или больше) маршрутизатора, которые могут вещать трафик. Если ничего не сделать, мультикастовый трафик будет дублироваться - оба маршрутизатора ведь будут получать Report от клиентов. Во избежание этого существует механизм выбора Querier - опрашивателя. Тот кто победит, будет посылать Query, мониторить Report и реагировать на Leave, ну и, соответственно, он будет отправлять и трафик в сегмент. Проигравший же будет только слушать Report и держать руку на пульсе.
Выборы происходят довольно просто и интуитивно понятно.
Рассмотрим ситуацию с момента включения маршрутизаторов R1 и R2.
1)
Активировали IGMP на интерфейсах.
2)
Сначала по умолчанию каждый из них считает себя Querier.
3)
Каждый отправляет IGMP General Query в сеть. Главная цель - узнать, есть ли клиенты, а параллельно - заявить другим маршрутизаторам в сегменте, если они есть, о своём желании участвовать в выборах.
4)
General Query получают все устройства в сегменте, в том числе и другие IGMP-маршрутизаторы.
5)
Получив такое сообщение от соседа, каждый маршрутизатор оценивает, кто достойнее.
6)
Побеждает маршрутизатор с меньшим IP
(указан в поле Source IP пакета IGMP Query). Он становится Querier, все другие - Non-Querier.
7)
Non-Querier запускает таймер, который обнуляется каждый раз, как приходит Query с меньшим IP-адресом. Если до истечения таймера (больше 100 секунд: 105-107) маршрутизатор не получит Query с меньшим адресом, он объявляет себя Querier и берёт на себя все соответствующие функции.
8)
Если Querier получает Query с меньшим адресом, он складывает с себя эти обязанности. Querier"ом становится другой маршрутизатор, у которого IP меньше.
Тот редкий случай, когда меряются, у кого меньше.
Выборы Querier очень важная процедура в мультикасте, но некоторые коварные производители, не придерживающиеся RFC, могут вставить крепкую палку в колёса. Я сейчас говорю о IGMP Query с адресом источника 0.0.0.0, которые могут генерироваться коммутатором. Такие сообщения не должны участвовать в выборе Querier, но надо быть готовыми ко всему. Вот пример весьма сложной долгоиграющей проблемы.
Ещё пара слов о других версиях IGMP
Версия 1 отличается по сути только тем, что в ней нет сообщения Leave . Если клиент не хочет больше получать трафик данной группы, он просто перестаёт посылать Report в ответ на Query. Когда не останется ни одного клиента, маршрутизатор по таймауту перестанет слать трафик.Кроме того, не поддерживаются выборы Querier . За избежание дублирования трафика отвечает вышестоящий протокол, например, PIM, о котором мы будем говорить .
Версия 3 поддерживает всё то, что поддерживает IGMPv2, но есть и ряд изменений. Во-первых, Report отправляется уже не на адрес группы, а на мультикастовый служебный адрес 224.0.0.22 . А адрес запрашиваемой группы указан только внутри пакета. Делается это для упрощения работы IGMP Snooping, о котором мы поговорим .
Во-вторых, что более важно, IGMPv3 стал поддерживать SSM в чистом виде. Это так называемый . В этом случае клиент может не просто запросить группу, но также указать список источников, от которых он хотел бы получать трафик или наоборот не хотел бы. В IGMPv2 клиент просто запрашивает и получает трафик группы, не заботясь об источнике.

Итак, IGMP предназначен для взаимодействия клиентов и маршрутизатора. Поэтому, возвращаясь к Примеру II , где нет маршрутизатора, мы можем авторитетно заявить - IGMP там - не более, чем формальность. Маршрутизатора нет, и клиенту не у кого запрашивать мультикастовый поток. А заработает видео по той простой причине, что поток и так льётся от коммутатора - надо только подхватить его.
Напомним, что IGMP не работает для IPv6. Там существует протокол .
Повторим ещё раз
*Дамп отфильтрован по IGMP* .
1. Первым делом маршрутизатор отправил свой IGMP General Query после включения IGMP на его интерфейсе, чтобы узнать, есть ли получатели и заявить о своём желании быть Querier. На тот момент никого не было в этой группе.
2. Далее появился клиент, который захотел получать трафик группы 224.2.2.4 и он отправил свой IGMP Report. После этого пошёл трафик на него, но он отфильтрован из дампа.
3. Потом маршрутизатор решил зачем-то проверить - а нет ли ещё клиентов и отправил IGMP General Query ещё раз, на который клиент вынужден ответить (4 ).
5. Периодически (раз в минуту) маршрутизатор проверяет, что получатели по-прежнему есть, с помощью IGMP General Query, а узел подтверждает это с помощью IGMP Report.
6. Потом он передумал и отказался от группы, отправив IGMP Leave.
7. Маршрутизатор получил Leave и, желая убедиться, что больше никаких других получателей нет, посылает IGMP Group Specific Query… дважды. И по истечении таймера перестаёт передавать трафик сюда.
8. Однако передавать IGMP Query в сеть он по-прежнему продолжает. Например, на тот случай, если вы плеер не отключали, а просто где-то со связью проблемы. Потом связь восстанавливается, но клиент-то Report не посылает сам по себе. А вот на Query отвечает. Таким образом поток может восстановиться без участия человека.
И ещё раз
IGMP - протокол, с помощью которого маршрутизатор узнаёт о наличии получателей мультикастового трафика и об их отключении.- посылается клиентом при подключении и в ответ на IGMP Query. Означает, что клиент хочет получать трафик конкретной группы.
- посылается маршрутизатором периодически, чтобы проверить какие группы сейчас нужны. В качестве адреса получателя указывается 224.0.0.1.
IGMP Group Sepcific Query - посылается маршрутизатором в ответ на сообщение Leave, чтобы узнать есть ли другие получатели в этой группе. В качестве адреса получателя указывается адрес мультикастовой группы.
- посылается клиентом, когда тот хочет покинуть группу.
Querier - если в одном широковещательном сегменте несколько маршрутизаторов, который могут вещать, среди них выбирается один главный - Querier. Он и будет периодически рассылать Query и передавать трафик.
Подробное описание всех терминов .
PIM
Итак, мы разобрались, как клиенты сообщают ближайшему маршрутизатору о своих намерениях. Теперь неплохо было бы передать трафик от источника получателю через большую сеть.Если вдуматься, то мы стоим перед довольной сложной проблемой - источник только вещает на группу, он ничего не знает о том, где находятся получатели и сколько их.
Получатели и ближайшие к ним маршрутизаторы знают только, что им нужен трафик конкретной группы, но понятия не имеют, где находится источник и какой у него адрес.
Как в такой ситуации доставить трафик?
Существует несколько протоколов маршрутизации мультикастового трафика: , - все они по-разному решают такую задачу. Но стандартом де факто стал PIM - Protocol Independent Multicast
.
Другие подходы настолько нежизнеспособны, что порой даже их разработчики практически признают это. Вот, например, выдержка из RFC по протоколу CBT:
CBT version 2 is not, and was not, intended to be backwards compatible with version 1; we do not expect this to cause extensive compatibility problems because we do not believe CBT is at all widely deployed at this stage.
PIM имеет две версии, которые можно даже назвать двумя различными протоколами в принципе, уж сильно они разные:
- PIM Dense Mode (DM)
- PIM Sparse Mode (SM)
PIM Dense Mode
пытается решить проблему доставки мультиакста в лоб. Он заведомо предполагает, что получатели есть везде, во всех уголках сети. Поэтому изначально он наводняет всю сеть мультикастовым трафиком, то есть рассылает его во все порты, кроме того, откуда он пришёл. Если потом оказывается, что где-то он не нужен, то эта ветка «отрезается» с помощью специального сообщения PIM Prune - трафик туда больше не отправляется.Но через некоторое время в эту же ветку маршрутизатор снова пытается отправить мультикаст - вдруг там появились получатели. Если не появились, ветка снова отрезается на определённый период. Если клиент на маршрутизаторе появился в промежутке между этими двумя событиями, отправляется сообщение Graft - маршрутизатор запрашивает отрезанную ветку обратно, чтобы не ждать, пока ему что-то перепадёт.
Как видите, здесь не стоит вопрос определения пути к получателям - трафик достигнет их просто потому, что он везде.
После «обрезания» ненужных ветвей остаётся дерево, вдоль которого передаётся мультикастовый трафик. Это дерево называется SPT - Shortest Path Tree
.
Оно лишено петель и использует кратчайший путь от получателя до источника. По сути оно очень похоже на Spanning Tree в , где корнем является источник.
SPT - это конкретный вид дерева - дерево кратчайшего пути. А вообще любое мультикастовое дерево называется .
Предполагается, что PIM DM должен использоваться в сетях с высокой плотностью мультикастовых клиентов, что и объясняет его название (Dense). Но реальность такова, что эта ситуация - скорее, исключение, и зачастую PIM DM нецелесообразен.
Что нам действительно важно сейчас - это механизм избежания петель.
Представим такую сеть:

Один источник, один получатель и простейшая IP-сеть между ними. На всех маршрутизаторах запущен PIM DM.
Что произошло бы, если бы не было специального механизма избежания петель?
Источник отправляет мультикастовый трафик. R1 его получает и в соответствии с принципами PIM DM отправляет во все интерфейсы, кроме того, откуда он пришёл - то есть на R2 и R3.
R2 поступает точно так же, то есть отправляет трафик в сторону R3. R3 не может определить, что это тот же самый трафик, который он уже получил от R1, поэтому пересылает его во все свои интерфейсы. R1 получит копию трафика от R3 и так далее. Вот она - петля.
Что же предлагает PIM в такой ситуации? RPF - Reverse Path Forwarding
. Это главный принцип передачи мультикастового трафика в PIM (любого вида: и DM и SM) - трафик от источника должен приходить по кратчайшему пути.
То есть для каждого полученного мультикастового пакета производится проверка на основе таблицы маршрутизации, оттуда ли он пришёл.
1) Маршрутизатор смотрит на адрес источника мультикастового пакета.
2) Проверяет таблицу маршрутизации, через какой интерфейс доступен адрес источника.
3) Проверяет интерфейс, через который пришёл мультикастовый пакет.
4) Если интерфейсы совпадают - всё отлично, мультикастовый пакет пропускается, если же данные приходят с другого интерфейса - они будут отброшены.
В нашем примере R3 знает, что кратчайший путь до источника лежит через R1 (статический или динамический маршрут). Поэтому мультикастовые пакеты, пришедшие от R1, проходят проверку и принимаются R3, а те, что пришли от R2, отбрасываются.

Такая проверка называется RPF-Check
и благодаря ей даже в более сложных сетях петли в MDT не возникнут.
Этот механизм важен нам, потому что он актуален и в PIM-SM и работает там точно также.
Как видите, PIM опирается на таблицу юникастовой маршрутизации, но, во-первых, сам не маршрутизирует трафик, во-вторых, ему не важно, кто и как наполнял таблицу.
Останавливаться здесь и подробно рассматривать работу PIM DM мы не будем - это устаревший протокол с массой недостатков (ну, как ).
Однако PIM DM может применяться в некоторых случаях. Например, в совсем небольших сетях, где поток мультикаста небольшой.

PIM Sparse Mode
Совершенно другой подход применяет PIM SM . Несмотря на название (разреженный режим), он с успехом может применяться в любой сети с эффективностью как минимум не хуже, чем у PIM DM.Здесь отказались от идеи безусловного наводнения мультикастом сети. Заинтересованные узлы самостоятельно запрашивают подключение к дереву с помощью сообщений PIM Join .
Если маршрутизатор не посылал Join, то и трафик ему отправляться не будет.
Для того, чтобы понять, как работает PIM, начнём с уже знакомой нам простой сети с одним PIM-маршрутизатором:
Из настроек на R1 надо включить возможность маршрутизации мультикаста, PIM SM на двух интерфейсах (в сторону источника и в сторону клиента) и IGMP в сторону клиента. Помимо прочих базовых настроек, конечно (IP, IGP).
С этого момента вы можете расчехлить GNS и собирать лабораторию. Достаточно подробно о том, как собрать стенд для мультикаста я рассказал в этой .
R1(config)#ip multicast-routing
R1(config)#int fa0/0
R1(config-if)#ip pim sparse-mode
R1(config-if)#int fa1/0
R1(config-if)#ip pim sparse-mode
Cisco тут как обычно отличается своим особенным подходом: при активации PIM на интерфейсе, автоматически активируется и IGMP. На всех интерфейсах, где активирован PIM, работает и IGMP.
В то же время у других производителей два разных протокола включаются двумя разными командами: отдельно IGMP, отдельно PIM.
Простим Cisco эту странность? Вместе со всеми остальными?Плюс, возможно, потребуется настроить адрес RP (ip pim rp-address 172.16.0.1 , например). Об этом позже, пока примите как данность и смиритесь.
Проверим текущее состояние таблицы мультикастовой маршрутизации для группы 224.2.2.4:

После того, как на источнике вы запустите вещание, надо проверить таблицу ещё раз.

Давайте разберём этот немногословный вывод.
Запись вида (*, 225.0.1.1)
называется , /читается старкомаджи
/ и сообщает нам о получателях. Причём не обязательно речь об одном клиенте-компьютере, вообще это может быть и, например, другой PIM-маршрутизатор. Важно то, в какие интерфейсы надо передавать трафик.
Если список нисходящих интерфейсов (OIL) пуст - Null
, значит нет получателей - а мы их пока не запускали.
Запись (172.16.0.5, 225.0.1.1) называется , /читается эскомаджи / и говорит о том, что известен источник. В нашем случае источник с адресом 172.16.0.5 вещает трафик для группы 224.2.2.4. Мультикастовый трафик приходит на интерфейс FE0/1 - это восходящий (Upstream ) интерфейс.
Итак, нет клиентов. Трафик от источника доходит до маршрутизатора и на этом его жизнь кончается. Давайте добавим теперь получателя - настроим приём мультикаста на ПК.
ПК отсылает IGMP Report, маршрутизатор понимает, что появились клиенты и обновляет таблицу мультикастовой маршрутизации.
Теперь она выглядит так:

Появился и нисходящий интерфейс: FE0/0, что вполне ожидаемо. Причём он появился как в (*, G), так и в (S, G). Список нисходящих интерфейсов называется OIL - Outgoing Interface List .
Добавим ещё одного клиента на интерфейс FE1/0:

(S, G): Когда мультикастовый трафик с адресом назначения 224.2.2.4 от источника 172.16.0.5 приходит на интерфейс FE0/1, его копии нужно отправить в FE0/0 и FE1/0.
Но это был очень простой пример - один маршрутизатор сразу знает и адрес источника и где находятся получатели. Фактически даже деревьев тут никаких нет - разве что вырожденное. Но это помогло нам разобраться с тем, как взаимодействуют PIM и IGMP.
Чтобы разобраться с тем, что такое PIM, обратимся к сети гораздо более сложной

Предположим, что уже настроены все IP-адреса в соответствии со схемой. На сети запущен IGP для обычной юникастовой маршрутизации.
Клиент1
, например, может пинговать Сервер-источник.

Но пока не запущен PIM, IGMP, клиенты не запрашивают каналы.
Итак, момент времени 0.
Включаем мультикастовую маршрутизацию на всех пяти маршрутизаторах:
RX(config)#ip multicast-routing
PIM включается непосредственно на всех интерфейсах всех маршрутизаторов (в том числе на интерфейсе в сторону Сервера-источника и клиентов):
RX(config)#int FEX/X
IGMP, по идее должен включаться на интерфейсах в сторону клиентов, но, как мы уже отметили выше, на оборудовании Cisco он включается автоматически вместе с PIM.
Первое, что делает PIM - устанавливает соседство. Для этого используются сообщения . При активации PIM на интерфейсе с него отправляется PIM Hello на адрес 224.0.0.13 с TTL равным 1. Это означает, что соседями могут быть только маршрутизаторы, находящиеся в одном широковещательном домене.

Как только соседи получили приветствия друг от друга:

Теперь они готовы принимать заявки на мультикастовые группы.
Если мы сейчас запустим в вольер клиентов с одной стороны и включим мультикастовый поток с сервера с другой, то R1 получит поток трафика, а R4 получит IGMP Report при попытке клиента подключиться. В итоге R1 не будет знать ничего о получателях, а R4 об источнике.

Неплохо было бы если бы информация об источнике и о клиентах группы была собрана где-то в одном месте. Но в каком?
Такая точка встречи называется Rendezvous Point - RP
. Это центральное понятие PIM SM. Без неё ничего бы не работало. Здесь встречаются источник и получатели.
Все PIM-маршрутизаторы должны знать, кто является RP в домене, то есть знать её IP-адрес.
Чтобы построить дерево MDT, в сети выбирается в качестве RP некая центральная точка, которая,
- отвечает за изучение источника,
- является точкой притяжения сообщений Join от всех заинтересованных.
Пусть пока R2 будет выполнять роль RP.
Чтобы увеличить надёжность, обычно выбирается адрес Loopback-интерфейса. Поэтому на всех
маршрутизаторах выполняется команда:
RX(config)#ip pim rp-address 2.2.2.2
Естественно, этот адрес должен быть доступен по таблице маршрутизации со всех точек.
Ну и поскольку адрес 2.2.2.2 является RP, на интерфейсе Loopback 0
на R2 желательно тоже активировать PIM.
R2(config)#interface Loopback 0
RX(config-if)#ip pim sparse-mode
Сразу после этого R4 узнает об источнике трафика для группы 224.2.2.4:

И даже передаёт трафик:

На интерфейс FE0/1 приходит 362000 б/с, и через интерфейс FE0/0 они передаются.
Всё, что мы сделали:
Включили возможность маршрутизации мультикастового трафика (ip multicast-routing
)
Активировали PIM на интерфейсах (ip pim sparse-mode
)
Указали адрес RP (ip pim rp-adress X.X.X.X
)
Всё, это уже рабочая конфигурация и можно приступать к разбору, ведь за кулисами скрывается гораздо больше, чем видно на сцене.
Полная конфигурация с PIM.
Разбор полётов
Ну так и как же в итоге всё работает? Как RP узнаёт где источник, где клиенты и обеспечивает связь между ними?Поскольку всё затевается ради наших любимых клиентов, то, начав с них, рассмотрим в деталях весь процесс.
1) Клиент 1 отправляет IGMP Report для группы 224.2.2.4

2) R4 получает этот запрос, понимает, что есть клиент за интерфейсом FE0/0, добавляет этот интерфейс в OIL и формирует запись (*, G).

Здесь видно восходящий интерфейс FE0/1, но это не значит, что R4 получает трафик для группы 224.2.2.4. Это говорит лишь о том, что единственное место, откуда сейчас он может получать - FE0/1, потому что именно там находится RP. Кстати, здесь же указан и сосед, который прошёл RPF-Check - R2: 10.0.2.24. Ожидаемо.
R4 называется - LHR (Last Hop Router) - последний маршрутизатор на пути мультикастового трафика, если считать от источника. Иными словами - это маршрутизатор, ближайший к получателю. Для Клиента1 - это R4, для Клиента2 - это R5.
3) Поскольку на R4 пока нет мультикастового потока (он его не запрашивал прежде), он формирует сообщение PIM Join и отправляет его в сторону RP (2.2.2.2).

PIM Join отправляется мультикастом на адрес 224.0.0.13. «В сторону RP» означает через интерфейс, который указан в таблице маршрутизации, как outbound для того адреса, который указан внутри пакета. В нашем случае это 2.2.2.2 - адрес RP. Такой Join обозначается ещё как Join (*,G)
и говорит: «Не важно, кто источник, мне нужен трафик группы 224.2.2.4».
То есть каждый маршрутизатор на пути должен обработать такой Join и при необходимости отправить новый Join в сторону RP. (Важно понимать, что если на маршрутизаторе уже есть эта группа, он не будет отправлять выше Join - он просто добавит интерфейс, с которого пришёл Join, в OIL и начнёт передавать трафик).
В нашем случае Join ушёл в FE0/1:

4) R2, получив Join, формирует запись (*, G) и добавляет интерфейс FE0/0 в OIL. Но Join отсылать уже некуда - он сам уже RP, а про источник пока ничего не известно.
Таким образом RP узнаёт о том, где находятся клиенты.
Если Клиент 2
тоже захочет получать мультикастовый трафик для той же группы, R5 отправит PIM Join в FE0/1, потому что за ним находится RP, R3, получив его, формирует новый PIM Join и отправляет в FE1/1 - туда, где находится RP.
То есть Join путешествует так узел за узлом, пока не доберётся до RP или до другого маршрутизатора, где уже есть клиенты этой группы.

Итак, R2 - наш RP - сейчас знает о том, что за FE0/0 и FE1/0 у него есть получатели для группы 224.2.2.4.
Причём неважно, сколько их там - по одному за каждым интерфейсом или по сто - поток трафика всё равно будет один на интерфейс.
Если изобразить графически то, что мы получили, то это будет выглядеть так:

Отдалённо напоминает дерево, не так ли? Поэтому оно так и называется - RPT - Rendezvous Point Tree
. Это дерево с корнем в RP, а ветви которого простираются до клиентов.
Более общий термин, как мы упоминали выше, - MDT - Multicast Distribution Tree
- дерево, вдоль которого распространяется мультикастовый поток. Позже вы увидите разницу между MDT и RPT.
5)
Теперь врубаем сервер. Как мы уже выше обсуждали, он не волнуется о PIM, RP, IGMP - он просто вещает. А R1 получает этот поток. Его задача - доставить мультикаст до RP.
В PIM есть специальный тип сообщений - Register
. Он нужен для того, чтобы зарегистрировать источник мультикаста на RP.
Итак, R1 получает мультикастовый поток группы 224.2.2.4:


R1 является FHR (First Hop Router) - первый маршрутизатор на пути мультикастового трафика или ближайший к источнику.

Обратите внимание на стек протоколов. Поверх юникастового IP и заголовка PIM идёт изначальный мультикастовый IP, UDP и данные.
Теперь, в отличие от всех других, пока известных нам сообщений PIM, в адресе получателя указан 2.2.2.2, а не мультикастовый адрес.
Такой пакет доставляется до RP по стандартным правилам юникастовой маршрутизации и несёт в себе изначальный мультикастовый пакет, то есть это… это же туннелирование!
На сервере 172.16.0.5 работает приложение, которое может передавать пакеты только на широковещательный адрес 255.255.255.255, с портом получателя UDP 10999.
Этот трафик надо доставить к клиентам 1 и 2:
Клиенту 1 в виде мультикаст трафика с адресом группы 239.9.9.9.
А в сегмент клиента 2, в виде широковещательных пакетов на адрес 255.255.255.255.
Замечание к топологии : в этой задаче только маршрутизаторы R1, R2, R3 находятся под управлением администраторов нашей сети. То есть, конфигурацию изменять можно только на них.
Сервер 172.16.0.5 передает мультикаст трафик на группы 239.1.1.1 и 239.2.2.2.
Настроить сеть таким образом, чтобы трафик группы 239.1.1.1 не передавался в сегмент между R3 и R5, и во все сегменты ниже R5.
Но при этом, трафик группы 239.2.2.2 должен передаваться без проблем.
То же, что Source DR, только для получателей мультикастового трафика - .
Пример топологии:

Receiver DR ответственен за отправку на RP PIM Join. В вышеприведённой топологии, если оба маршрутизатора отправят Join, то оба будут получать мультикастовый трафик, но в этом нет необходимости. Только DR отправляет Join. Второй просто мониторит доступность DR.
Поскольку DR отправляет Join, то он же и будет вещать трафик в LAN. Но тут возникает закономерный вопрос - а что, если PIM DR"ом стал один, а IGMP Querier"ом другой? А ситуация-то вполне возможна, ведь для Querier чем меньше IP, тем лучше, а для DR, наоборот.
В этом случае DR"ом выбирается тот маршрутизатор, который уже является Querier и такая проблема не возникает.

Правила выбора Receiver DR точно такие же, как и Source DR.
Проблема двух одновременно передающих маршрутизаторов может возникнуть и в середине сети, где нет ни конечных клиентов, ни источников - только маршрутизаторы.
Очень остро этот вопрос стоял в PIM DM, где это была совершенно рядовая ситуация из-за механизма Flood and Prune.
Но и в PIM SM она не исключена.
Рассмотрим такую сеть:

Здесь три маршрутизатора находятся в одном сегменте сети и, соответственно, являются соседями по PIM. R1 выступает в роли RP.
R4 отправляет PIM Join в сторону RP. Поскольку этот пакет мультикастовый он попадает и на R2 и на R3, и оба они обработав его, добавляют нисходящий интерфейс в OIL.
Тут бы должен сработать механизм выбора DR, но и на R2 и на R3 есть другие клиенты этой группы, и обоим маршрутизаторам так или иначе придётся отправлять PIM Join.
Когда мультикастовый трафик приходит от источника на R2 и R3, в сегмент он передаётся обоими маршрутизаторами и задваивается там. PIM не пытается предотвратить такую ситуацию - тут он действует по факту свершившегося преступления - как только в свой нисходящий интерфейс для определённой группы (из списка OIL) маршрутизатор получает мультикастовый трафик этой самой группы, он понимает: что-то не так - другой отправитель уже есть в этом сегменте.

Тогда маршрутизатор отправляет специальное сообщение .
Такое сообщение помогает выбрать PIM Forwarder
- тот маршрутизатор, который вправе вещать в данном сегменте.

Не надо его путать с PIM DR. Во-первых, PIM DR отвечает за отправку сообщений PIM Join и Prune , а PIM Forwarder - за отправку трафика . Второе отличие - PIM DR выбирается всегда и в любых сетях при установлении соседства, А PIM Forwrder только при необходимости - когда получен мультикастовый трафик с интерфейса из списка OIL.
Выбор RP
Выше мы для простоты задавали RP вручную командой ip pim rp-address X.X.X.X .И вот как выглядела команда :
Но представим совершенно невозможную в современных сетях ситуацию - R2 вышел из строя. Это всё - финиш. Клиент 2
ещё будет работать, поскольку произошёл SPT Switchover, а вот всё новое и всё, что шло через RP сломается, даже если есть альтернативный путь.
Ну и нагрузка на администратора домена. Представьте себе: на 50 маршрутизаторах перебить вручную как минимум одну команду (а для разных групп ведь могут быть разные RP).
Динамический выбор RP позволяет и избежать ручной работы и обеспечить надёжность - если одна RP станет недоступна, в бой вступит сразу же другая.
В данный момент существует один общепризнанный протокол, позволяющий это сделать - . Циска в прежние времена продвигала несколько неуклюжий , но сейчас он почти не используется, хотя циска этого не признаёт, и в мы имеем раздражающий рудимент в виде группы 224.0.1.40.
Надо на самом деле отдать должное протоколу Auto-RP. Он был спасением в прежние времена. Но с появлением открытого и гибкого Bootstrap, он закономерно уступил свои позиции.Итак, предположим, что в нашей сети мы хотим, чтобы R3 подхватывал функции RP в случае выхода из строя R2.
R2 и R3 определяются как кандидаты на роль RP - так они и называются C-RP . На этих маршрутизаторах настраиваем:
RX(config)interface Loopback 0
RX(config-if)ip pim sparse-mode
RX(config-if)exit
RX(config)#ip pim rp-candidate loopback 0
Но пока ничего не происходит - кандидаты пока не знают, как уведомить всех о себе.
Чтобы информировать все мультикастовые маршрутизаторы домена о существующих RP вводится механизм BSR - BootStrap Router . Претендентов может быть несколько, как и C-RP. Они называются соответственно C-BSR . Настраиваются они похожим образом.
Пусть BSR у нас будет один и для теста (исключительно) это будет R1.
R1(config)interface Loopback 0
R1(config-if)ip pim sparse-mode
R1(config-if)exit
R1(config)#ip pim bsr-candidate loopback 0
Сначала из всех C-BSR выбирается один главный BSR, который и будет всем заправлять. Для этого каждый C-BSR отправляет в сеть мультикастовый BootStrap Message (BSM)
на адрес 224.0.0.13 - это тоже пакет протокола PIM. Его должны принять и обработать все мультикастовые маршрутизаторы и после разослать во все порты, где активирован PIM. BSM передаётся не в сторону чего-то (RP или источника), в отличии, от PIM Join, а во все стороны. Такая веерная рассылка помогает достигнуть BSM всех уголков сети, в том числе всех C-BSR и всех C-RP. Для того, чтобы BSM не блуждали по сети бесконечно, применяется всё тот же механизм RPF - если BSM пришёл не с того интерфейса, за которым находится сеть отправителя этого сообщения, такое сообщение отбрасывается.
![]()
С помощью этих BSM все мультикастовые маршрутизаторы определяют самого достойного кандидата на основе приоритетов. Как только C-BSR получает BSM от другого маршрутизатора с бОльшим приоритетом, он прекращает рассылать свои сообщения. В результате все обладают одинаковой информацией.
На этом этапе, когда выбран BSR, благодаря тому, что его BSM разошлись уже по всей сети, C-RP знают его адрес и юникастом отправляют на него сообщения Candidte-RP-Advertisement , в которых они несут список групп, которые они обслуживают - это называется group-to-RP mapping . BSR все эти сообщения агрегирует и создаёт RP-Set - информационную таблицу: какие RP каждую группу обслуживают.

Далее BSR в прежней веерной манере рассылает те же BootStrap Message, которые на этот раз содержат RP-Set. Эти сообщения успешно достигают всех мультикастовых маршрутизаторов, каждый из которых самостоятельно делает выбор, какую RP нужно использовать для каждой конкретной группы.

BSR периодически делает такие рассылки, чтобы с одной стороны все знали, что информация по RP ещё актуальна, а с другой C-BSR были в курсе, что сам главный BSR ещё жив.
RP, кстати, тоже периодически шлют на BSR свои анонсы Candidate-RP-Advertisement.
Фактически всё, что нужно сделать для настройки автоматического выбора RP - указать C-RP и указать C-BSR - не так уж много работы, всё остальное за вас сделает PIM.
Как всегда, в целях повышения надёжности рекомендуется указывать интерфейсы Loopback в качестве кандидатов.
Завершая главу PIM SM, давайте ещё раз отметим важнейшие моменты
- Должна быть обеспечена обычная юникастовая связность с помощью IGP или статических маршрутов. Это лежит в основе алгоритма RPF.
- Дерево строится только после появления клиента. Именно клиент инициирует построение дерева. Нет клиента - нет дерева.
- RPF помогает избежать петель.
- Все маршрутизаторы должны знать о том, кто является RP - только с её помощью можно построить дерево.
- Точка RP может быть указана статически, а может выбираться автоматически с помощью протокола BootStrap.
- В первой фазе строится RPT - дерево от клиентов до RP - и Source Tree - дерево от источника до RP. Во второй фазе происходит переключение с построенного RPT на SPT - кратчайший путь от получателя до источника.
MDT - Multicast Distribution Tree
. Общий термин, описывающий любое дерево передачи мультикаста.
SPT - Shortest Path Tree
. Дерево с кратчайшим путём от клиента или RP до источника. В PIM DM есть только SPT. В PIM SM SPT может быть от источника до RP или от источника до получателя после того, как произошёл SPT Switchover. Обозначается записью - известен источник для группы.
Source Tree
- то же самое, что SPT.
RPT - Rendezvous Point Tree
. Дерево от RP до получателей. Используется только в PIM SM. Обозначается записью .
Shared Tree
- то же, что RPT. Называется так потому, что все клиенты подключены к одному общему дереву с корнем в RP.
Типы сообщений PIM Sparse Mode:
Hello
- для установления соседства и поддержания этих отношений. Также необходимы для выбора DR.
- запрос на подключение к дереву группы G. Не важно кто источник. Отправляется в сторону RP. С их помощью строится дерево RPT.
- Source Specific Join. Это запрос на подключение к дереву группы G с определённым источником - S. Отправляется в сторону источника - S. С их помощью строится дерево SPT.
Prune (*, G)
- запрос на отключение от дерева группы G, какие бы источники для неё не были. Отправляется в сторону RP. Так обрезается ветвь RPT.
Prune (S, G)
- запрос на отключение от дерева группы G, корнем которого является источник S. Отправляется в сторону источника. Так обрезается ветвь SPT.
Register
- специальное сообщение, внутри которого передаётся мультикаст на RP, пока не будет построено SPT от источника до RP. Передаётся юникастом от FHR на RP.
Register-Stop
- отправляется юникастом с RP на FHR, приказывая прекратить посылать мультикастовый трафик, инкапсулированный в Register.
- пакеты механизма BSR, которые позволяют выбрать маршрутизатор на роль BSR, а также передают информацию о существующих RP и группах.
Assert
- сообщение для выбора PIM Forwarder, чтобы в один сегмент не передавали трафик два маршрутизатора.
Candidate-RP-Advertisement
- сообщение, в котором RP отсылает на BSR информацию о том, какие группы он обслуживает.
RP-Reachable
- сообщение от RP, которым она уведомляет всех о своей доступности.
*Есть и другие типы сообщений в PIM, но это уже детали*
А давайте теперь попытаемся абстрагироваться от деталей протокола? И тогда становится очевидной его сложность.
1) Определение RP,
2) Регистрация источника на RP,
3) Переключение на дерево SPT.
Много состояний протокола, много записей в таблице мультикастовой маршрутизации. Можно ли что-то с этим сделать?
На сегодняшний день существует два диаметрально противоположных подхода к упрощению PIM: SSM и BIDIR PIM.
SSM
Всё, что мы описывали до сих пор - это ASM - Any Source Multicast . Клиентам безразлично, кто является источником трафика для группы - главное, что они его получают. Как вы помните в сообщении IGMPv2 Report запрашивается просто подключение к группе.SSM - Source Specific Multicast - альтернативный подход. В этом случае клиенты при подключении указывают группу и источник.
Что же это даёт? Ни много ни мало: возможность полностью избавиться от RP. LHR сразу знает адрес источника - нет необходимости слать Join на RP, маршрутизатор может сразу же отправить Join (S, G) в направлении источника и построить SPT.
Таким образом мы избавляемся от
- Поиска RP (протоколы Bootstrap и Auto-RP),
- Регистрации источника на мультикасте (а это лишнее время, двойное использование полосы пропускания и туннелирование)
- Переключения на SPT.
Ещё одна проблема, которая решается с помощью SSM - наличие нескольких источников. В ASM рекомендуется, чтобы адрес мультикастовой группы был уникален и только один источник вещал на него, поскольку в дереве RPT несколько потоков сольются, а клиент, получая два потока от разных источников, вероятно, не сможет их разобрать.
В SSM трафик от различных источников распространяется независимо, каждый по своему дереву SPT, и это уже становится не проблемой, а преимуществом - несколько серверов могут вещать одновременно. Если вдруг клиент начал фиксировать потери от основного источника, он может переключиться на резервный, даже не перезапрашивая его - он и так получал два потока.
Кроме того, возможный вектор атаки в сети с активированной мультикастовой маршрутизацией - подключение злоумышленником своего источника и генерирование большого объёма мультикастового трафика, который перегрузит сеть. В SSM такое практически исключено.
Для SSM выделен специальный диапазон IP-адресов: 232.0.0.0/8.
На маршрутизаторах для поддержки SSM включается режим PIM SSM.
Router(config)# ip pim ssm
IGMPv3 и MLDv2 поддерживают SSM в чистом виде.
При их использовании клиент может
- Запрашивать подключение к просто группе, без указания источников. То есть работает как типичный ASM.
- Запрашивать подключение к группе с определённым источником. Источников можно указать несколько - до каждого из них будет построено дерево.
- Запрашивать подключение к группе и указать список источников, от которых клиент не хотел бы получать трафик
IGMPv1/v2, MLDv1 не поддерживают SSM, но имеет место такое понятие, как SSM Mapping
. На ближайшем к клиенту маршрутизаторе (LHR) каждой группе ставится в соответствие адрес источника (или несколько). Поэтому если в сети есть клиенты, не поддерживающие IGMPv3/MLDv2, для них также будет построено SPT, а не RPT, благодаря тому, что адрес источника всё равно известен.
SSM Mapping может быть реализован как статической настройкой на LHR, так и посредством обращения к DNS-серверу.
Проблема SSM в том, что клиенты должны заранее знать адреса источников - никакой сигнализацией они им не сообщаются.
Поэтому SSM хорош в тех ситуациях, когда в сети определённый набор источников, их адреса заведомо известны и не будут меняться. А клиентские терминалы или приложения жёстко привязаны к ним.
Иными словами IPTV - весьма пригодная среда для внедрения SSM. Это хорошо описывает концепцию One-to-Many
- один источник, много получателей.
А что если в сети источники могут появляться спонтанно то там, то тут, вещать на одинаковые группы, быстро прекращать передачу и исчезать?
Например, такая ситуация возможна в сетевых играх или в ЦОД, где происходит репликация данных между различными серверами. Это концепция Many-to-Many
- много источников, много клиентов.
Как на это смотрит обычный PIM SM? Понятное дело, что инертный PIM SSM здесь совсем не подходит?
Вы только подумайте, какой хаос начнётся: бесконечные регистрации источников, перестроение деревьев, огромное количество записей (S, G) живущих по несколько минут из-за таймеров протокола.
На выручку идёт двунаправленный PIM (Bidirectional PIM, BIDIR PIM
). В отличие от SSM в нём напротив полностью отказываются от SPT и записей (S,G) - остаются только Shared Tree с корнем в RP.
И если в обычном PIM, дерево является односторонним - трафик всегда передаётся от источника вниз по SPT и от RP вниз по RPT - есть чёткое деление, где источник, где клиенты, то в двунаправленном от источника трафик к RP передаётся также вверх по Shared Tree - по тому же самому, по которому трафик течёт вниз к клиентам.
Это позволяет отказаться от регистрации источника на RP - трафик передаётся безусловно, без какой бы то ни было сигнализации и изменения состояний. Поскольку деревьев SPT нет вообще, то и SPT Switchover тоже не происходит.
Вот например:

Источник1
начал передавать в сеть трафик группы 224.2.2.4 одновременно с Источником2
. Потоки от них просто полились в сторону RP. Часть клиентов, которые находятся рядом начали получать трафик сразу, потому что на маршрутизаторах есть запись (*, G) (есть клиенты). Другая часть получает трафик по Shared Tree от RP. Причём получают они трафик от обоих источников одновременно.
То есть, если взять для примера умозрительную сетевую игру, Источник1
это первый игрок в стрелялке, который сделал выстрел, а Источник2
- это другой игрок, который сделал шаг в сторону. Информация об этих двух событиях распространилась по всей сети. И каждый
другой игрок (Получатель
) должен узнать об обоих этих событиях.
Если помните, то мы объяснили, зачем нужен процесс регистрации источника на RP - чтобы трафик не занимал канал, когда нет клиентов, то есть RP просто отказывался от него. Почему над этой проблемой мы не задумываемся сейчас? Причина проста: BIDIR PIM для ситуаций, когда источников много, но они вещают не постоянно, а периодически, относительно небольшими кусками данных. То есть канал от источника до RP не будет утилизироваться понапрасну.
Обратите внимание, что на изображении выше между R5 и R7 есть прямая линия, гораздо более короткая, чем путь через RP, но она не была использована, потому что Join идут в сторону RP согласно таблице маршрутизации, в которой данный путь не является оптимальным.
Выглядит довольно просто - нужно отправлять мультикастовые пакеты в направлении RP и всё, но есть один нюанс, который всё портит - RPF. В дереве RPT он требует, чтобы трафик приходил от RP и не иначе. А у нас он может приходить откуда угодно. Взять и отказаться от RPF мы, конечно, не можем - это единственный механизм, который позволяет избежать образования петель.
Поэтому в BIDIR PIM вводится понятие . В каждом сегменте сети, на каждой линии на эту роль выбирается тот маршрутизатор, чей маршрут до RP лучше.
В том числе это делается и на тех линиях, куда непосредственно подключены клиенты. В BIDIR PIM DF автоматически является DR.

Список OIL формируется только из тех интерфейсов, на которых маршрутизатор был выбран на роль DF.
Правила довольно прозрачны:
- Если запрос PIM Join/Leave приходит на тот интерфейс, который в данном сегменте является DF, он передаётся в сторону RP по стандартным правилам.
Вот, например, R3. Если запросы пришли в DF интерфейсы, что помечены красным кругом, он их передаёт на RP (через R1 или R2, в зависимости от таблицы маршрутизации). - Если запрос PIM Join/Leave пришёл на не DF интерфейс, он будет проигнорирован.
Допустим, что клиент, находящийся между R1 и R3, решил подключиться и отправил IGMP Report. R1 получает его через интерфейс, где он выбран DF (помечен красным кругом), и мы возвращаемся к предыдущему сценарию. А R3 получает запрос на интерфейс, который не является DF. R3 видит, что тут он не лучший, и игнорирует запрос. - Если мультикастовый трафик пришёл на DF интерфейс, он будет отправлен в интерфейсы из списка OIL и в сторону RP.
Например, Источник1 начал передавать трафик. R4 получает его в свой DF интерфейс и передаёт его и в другой DF-интерфейс - в сторону клиента и в сторону RP, - это важно, потому что трафик должен попасть на RP и распространиться по всем получателям. Также поступает и R3 - одна копия в интерфейсы из списка OIL - то есть на R5, где он будет отброшен из-за проверки RPF, и другая - в сторону RP. - Если мультикастовый трафик пришёл на не DF интерфейс, он должен быть отправлен в интерфейсы из списка OIL, но не будет
отправлен в сторону RP.
К примеру, Источник2 начал вещать, трафик дошёл до RP и начал распространяться вниз по RPT. R3 получает трафик от R1, и он не передаст его на R2 - только вниз на R4 и на R5.
Кстати, нет нужды более и в сообщениях Assert, ведь DF выбирается в каждом сегменте. В отличие от DR он отвечает не только за отправку Join к RP, но и за передачу трафика в сегмент, то есть ситуация, когда два маршрутизатора передают в одну подсеть трафик, исключена в BIDIR PIM.
Пожалуй, последнее, что нужно сказать о двунаправленном PIM, это особенности работы RP. Если в PIM SM RP выполнял вполне конкретную функцию - регистрация источника, то в BIDIR PIM RP - это некая весьма условная точка, к которой стремится трафик с одной стороны и Join от клиентов с другой. Никто не должен выполнять декапсуляцию, запрашивать построение дерева SPT. Просто на каком-то маршрутизаторе вдруг трафик от источников начинает передаваться в Shared Tree. Почему я говорю «на каком-то»? Дело в том, что в BIDIR PIM RP - абстрактная точка, а не конкретный маршрутизатор, в качестве адреса RP вообще может выступать несуществующий IP-адрес - главное, чтобы он был маршрутизируемый (такая RP называется ).
Все термины, касающиеся PIM, можно найти в .
Мультикаст на канальном уровне
Итак, позади долгая трудовая неделя с недосыпами, переработками, тестами - вы успешно внедрили мультикаст и удовлетворили клиентов, директора и отдел продаж.Пятница - не самый плохой день, чтобы обозреть творение и позволить себе приятный отдых.
Но ваш послеобеденный сон вдруг потревожил звонок техподдержки, потом ещё один и ещё - ничего не работает, всё сломалось. Проверяете - идут потери, разрывы. Всё сходится на одном сегменте из нескольких коммутаторов.
Расчехлили SSH, проверили CPU, проверили утилизацию интерфейсов и волосы дыбом - загрузка почти под 100% на всех интерфейсах одного VLAN"а. Петля! Но откуда ей взяться, если никаких работ не проводилось? Минут 10 проверки и вы заметили, что на восходящем интерфейсе к ядру у вас много входящего трафика, а на всех нисходящих к клиентам - исходящего. Для петли это тоже характерно, но как-то подозрительно: внедрили мультикаст, никаких работ по переключению не делали и скачок только в одном направлении.
Проверили список мультикастовых групп на маршрутизаторе - а там подписка на все возможные каналы и все на один порт - естественно, тот, который ведёт в этот сегмент.
Дотошное расследование показало, что компьютер клиента заражён и рассылает IGMP Query на все мультикастовые адреса подряд.
Потери пакетов начались, потому что коммутаторам пришлось пропускать через себя огромный объём трафика. Это вызвало переполнение буферов интерфейсов.
Главный вопрос - почему трафик одного клиента начал копироваться во все порты?
Причина этого кроется в природе мультикастовых MAC-адресов. Дело в том, пространство мультикастовых IP-адресов специальным образом отображается в пространство мультикастовых MAC-адресов. И загвоздка в том, что они никогда не будут использоваться в качестве MAC-адреса источника, а следовательно, не будут изучены коммутатором и занесены в таблицу MAC-адресов. А как поступает коммутатор с кадрами, адрес назначения которых не изучен? Он их рассылает во все порты. Что и произошло.
Это действие по умолчанию.

Мультикастовые MAC-адреса
Так какие же MAC-адреса получателей подставляются в заголовок Ethernet таких пакетов? Широковещательные? Нет. Существует специальный диапазон MAC-адресов, в которые отображаются мультикастовые IP-адреса.Эти специальные адреса начинаются так: 0x01005e и следующий 25-й бит должен быть 0 (попробуйте ответить, почему так ). Остальные 23 бита (напомню, всего их в МАС-адресе 48) переносятся из IP-адреса.
Здесь кроется некоторая не очень серьёзная, но проблема. Диапазон мультикастовых адресов определяется маской 224.0.0.0/4, это означает, что первые 4 бита зарезервированы: 1110, а оставшиеся 28 бит могут меняться. То есть у нас 2^28 мультикастовых IP-адресов и только 2^23 MAC-адресов - для отображения 1 в 1 не хватает 5 бит. Поэтому берутся просто последние 23 бита IP-адреса и один в один переносятся в MAC-адрес, остальные 5 отбрасываются.

Фактически это означает, что в один мультикастовый MAC-адрес будет отображаться 2^5=32 IP-адреса. Например, группы 224.0.0.1, 224.128.0.1, 225.0.0.1 и так до 239.128.0.1 все будут отображаться в один MAC-адрес 0100:5e00:0001.
Если взять в пример дамп потокового видео, то можно увидеть:
IP адрес - 224.2.2.4, MAC-адрес: 01:00:5E:02:02:04.
Есть также другие мультикастовые MAC-адреса, которые никак не относятся к IPv4-мультикаст (клик). Все они, кстати, характеризуются тем, что последний бит первого октета равен 1.
Естественно, ни на одной сетевой карте, не может быть настроен такой MAC-адрес, поэтому он никогда не будет в поле Source MAC Ethernet-кадра и никогда не попадёт в таблицу MAC-адресов. Значит такие кадры должны рассылаться как любой во все порты VLAN"а.
Всего, что мы рассматривали прежде, вполне достаточно для полноценной передачи любого мультикастового трафика от потокового видео до биржевых котировок. Но неужели мы в своём почти совершенном мире будем мирится с таким безобразием, как широковещательная передача того, что можно было бы передать избранным?
Вовсе нет. Специально для перфекционистов
придуман механизм .
Идея очень простая - коммутатор «слушает» проходящие через него IGMP-пакеты.
Для каждой группы отдельно он ведёт таблицу восходящих и нисходящих портов.
Если с порта пришёл IGMP Report для группы, значит там клиент, коммутатор добавляет его в список нисходящих для этой группы.
Если с порта пришёл IGMP Query для группы, значит там маршрутизатор, коммутатор добавляет его в список восходящих.
Таким образом формируется таблица передачи мультикастового трафика на канальном уровне.
В итоге, когда сверху приходит мультикастовый поток, он копируется только в нисходящие интерфейсы. Если на 16-портовом коммутаторе только два клиента, только им и будет доставлен трафик.

Гениальность этой идеи заканчивается тогда, когда мы задумываемся о её природе. Механизм предполагает, что коммутатор должен прослушивать трафик на 3-м уровне.
Впрочем, IGMP Snooping ни в какое сравнение не идёт с NAT по степени игнорирования принципов сетевого взаимодействия. Тем более, кроме экономии в ресурсах, он несёт в себе массу менее очевидных возможностей. Да и в общем-то в современном мире, коммутатор, который умеет заглядывать внутрь IP - явление не исключительное.
=====================Сервер 172.16.0.5 передает мультикаст трафик на группы 239.1.1.1, 239.2.2.2 и 239.0.0.x.
Настроить сеть таким образом, чтобы:
- клиент 1 не мог присоединиться к группе 239.2.2.2. Но при этом мог присоединиться к группе 239.0.0.x.
- клиент 2 не мог присоединиться к группе 239.1.1.1. Но при этом мог присоединиться к группе 239.0.0.x.Напоследок нетривиальная задачка по мультикасту (авторы не мы, в ответах будет ссылка на оригинал).
Самая простая схема:
С одной стороны сервер-источник, с дугой - компьютер, который готов принимать трафик.
Адрес мультикастового потока вы можете устанавливать сами.
И соответственно, два вопроса:
1. Что нужно сделать, чтобы компьютер мог получать поток и при этом не прибегать к мультикастовой маршрутизации?
2. Допустим, вы вообще не знаете, что такое мультикаст и не можете его настраивать, как передать поток от сервера к компьютеру?Задача легко ищется в поисковике, но попробуйте решить её сами.
Оставайтесь на связи.
